|
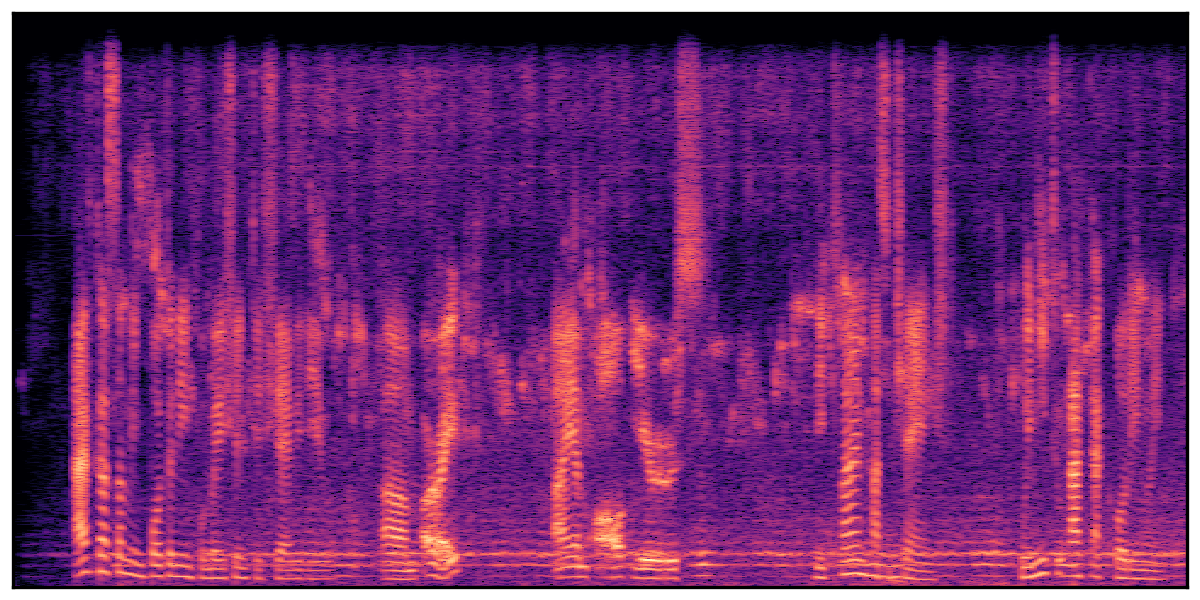
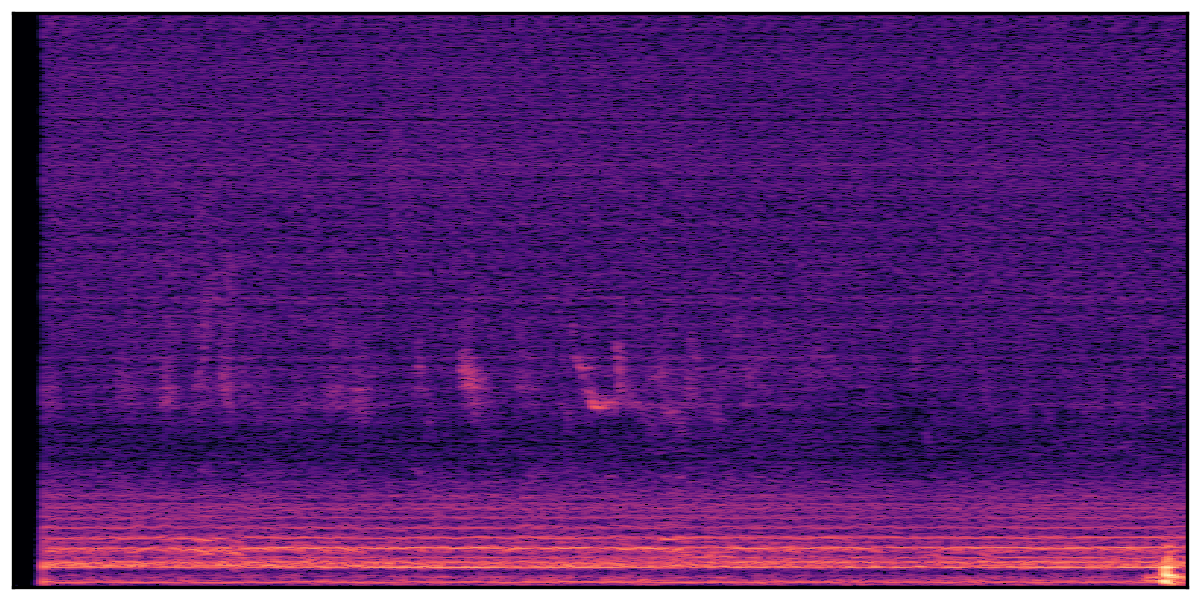
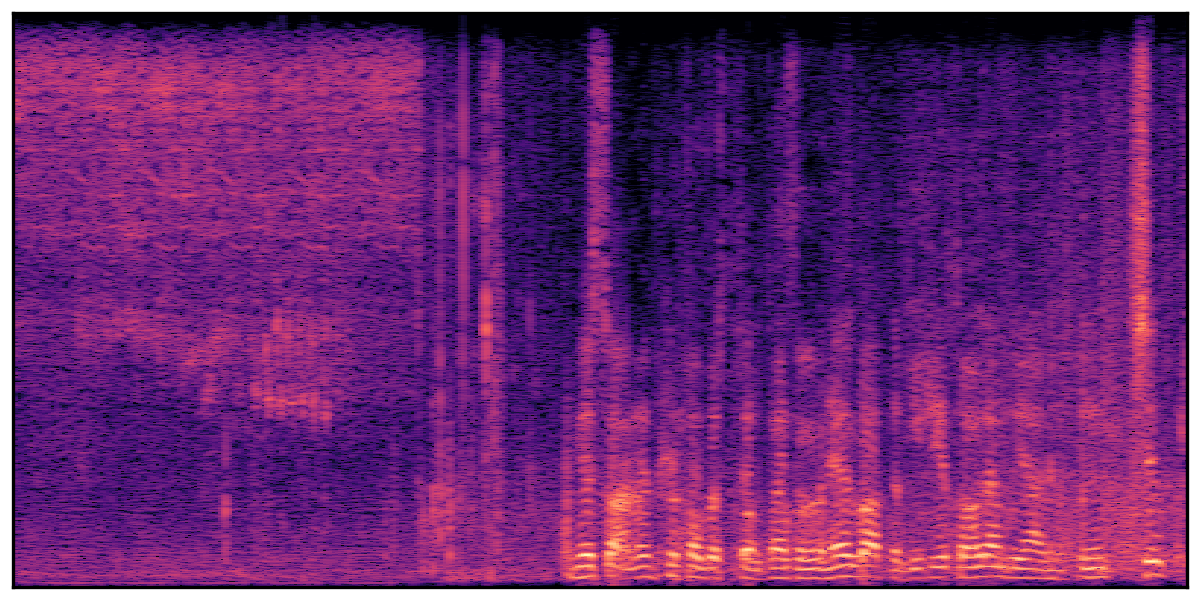
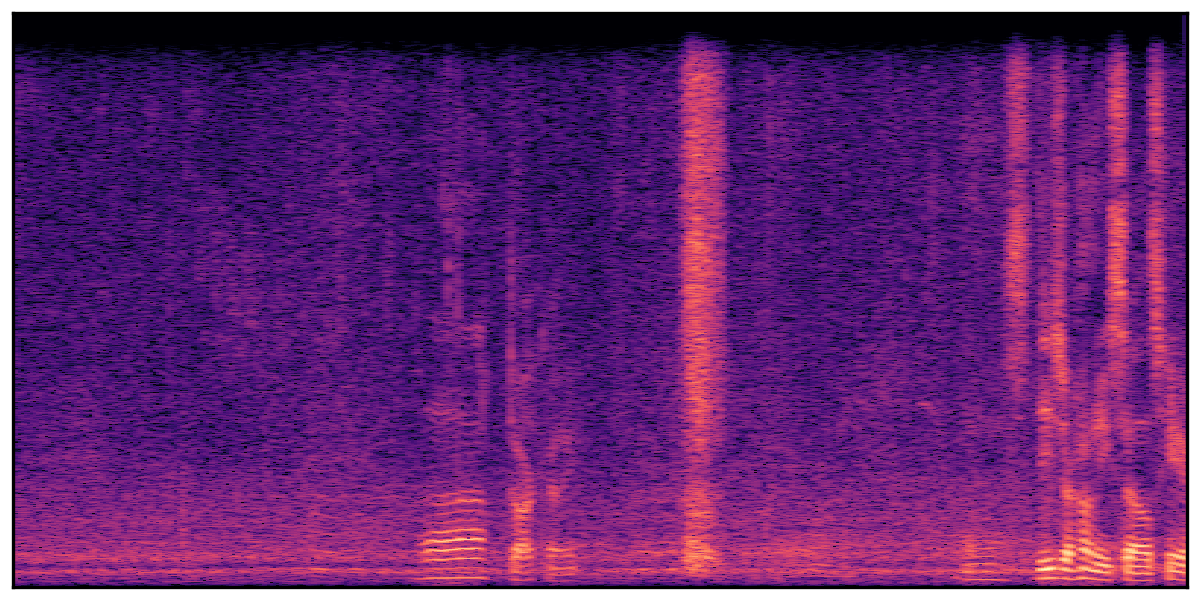
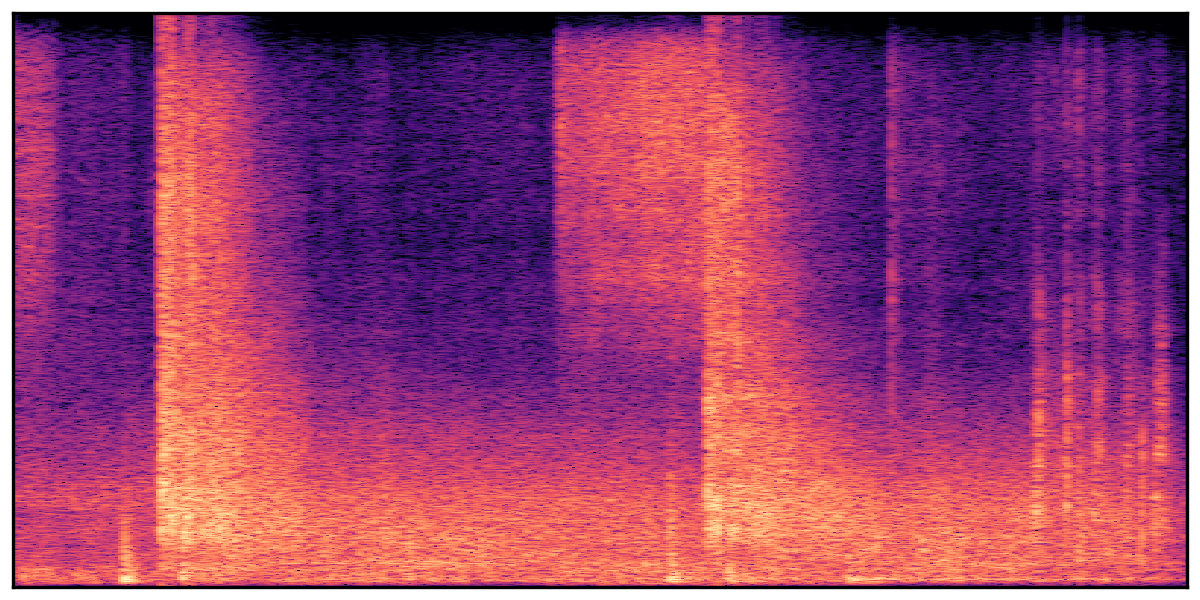
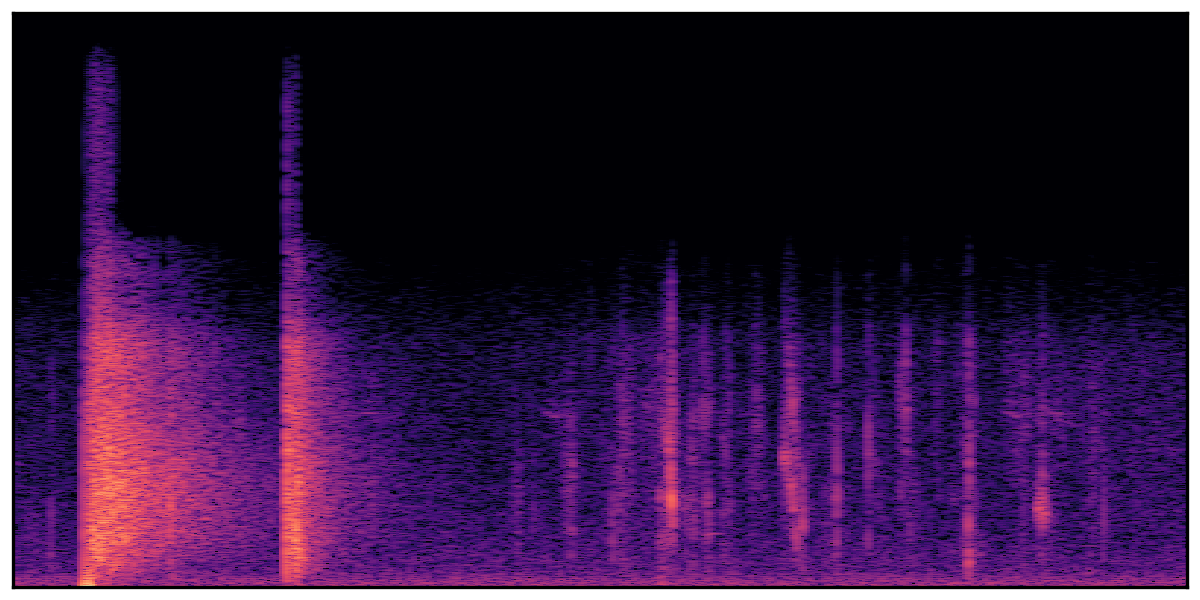
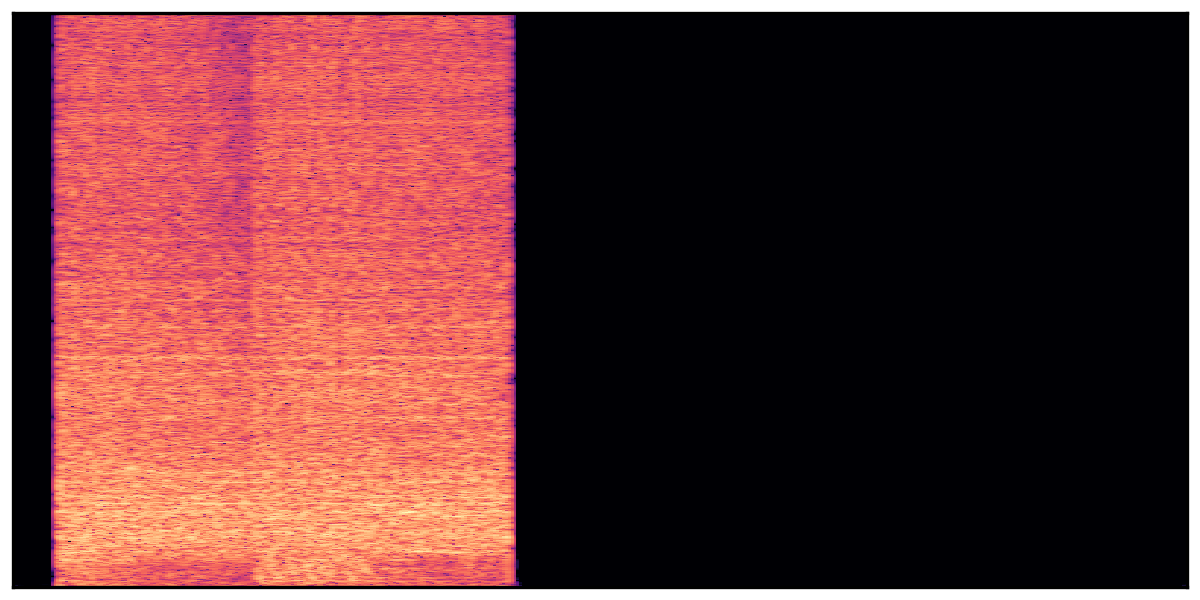
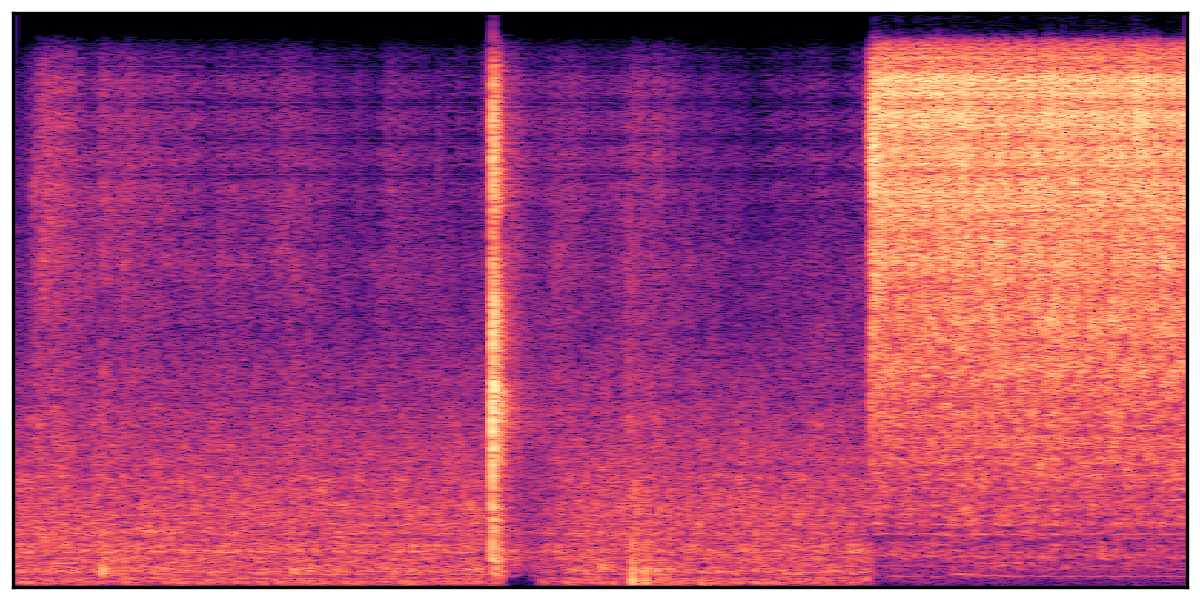
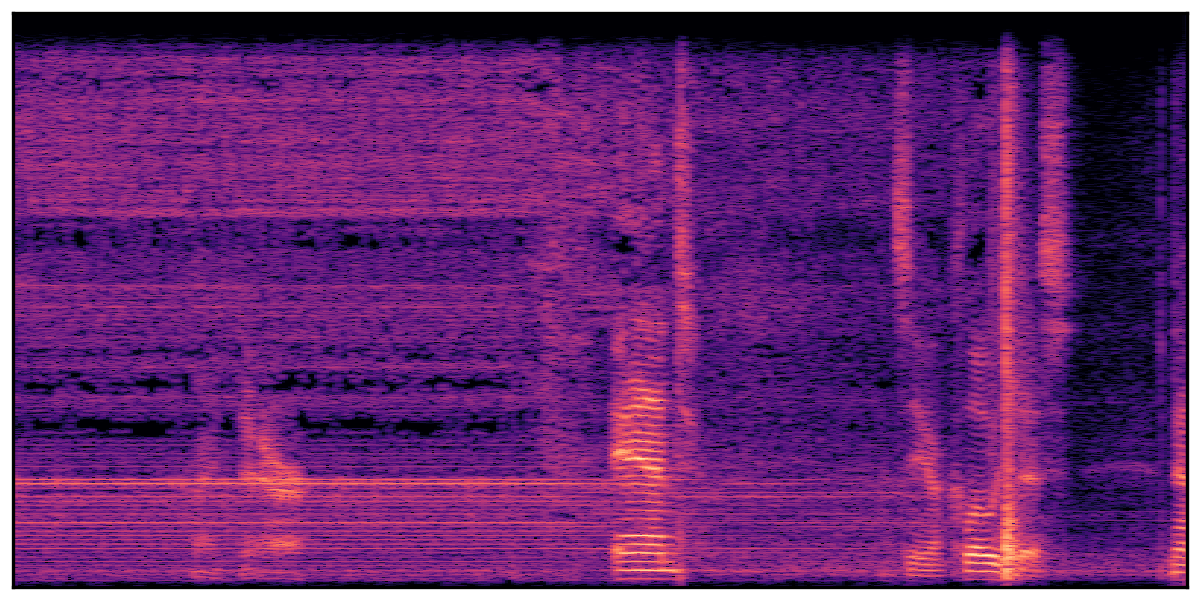
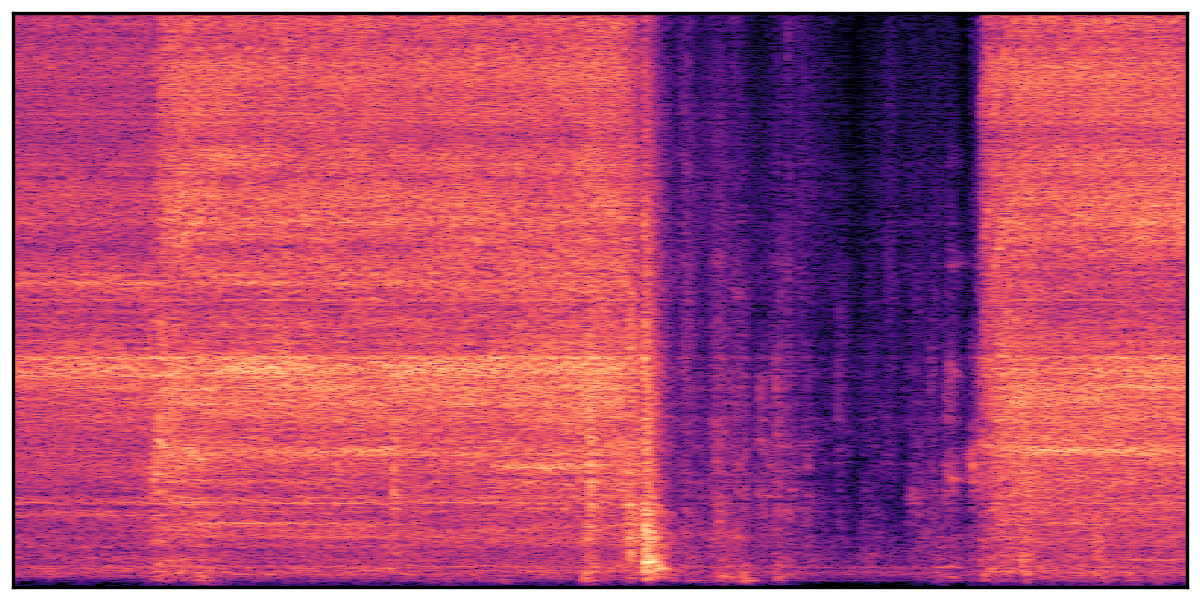
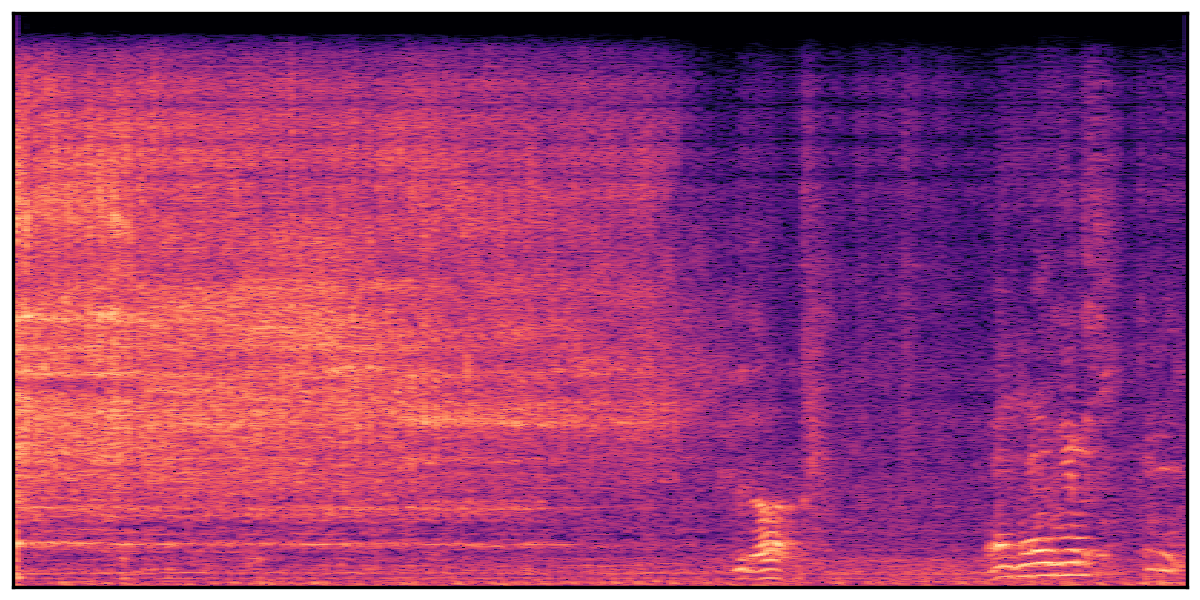
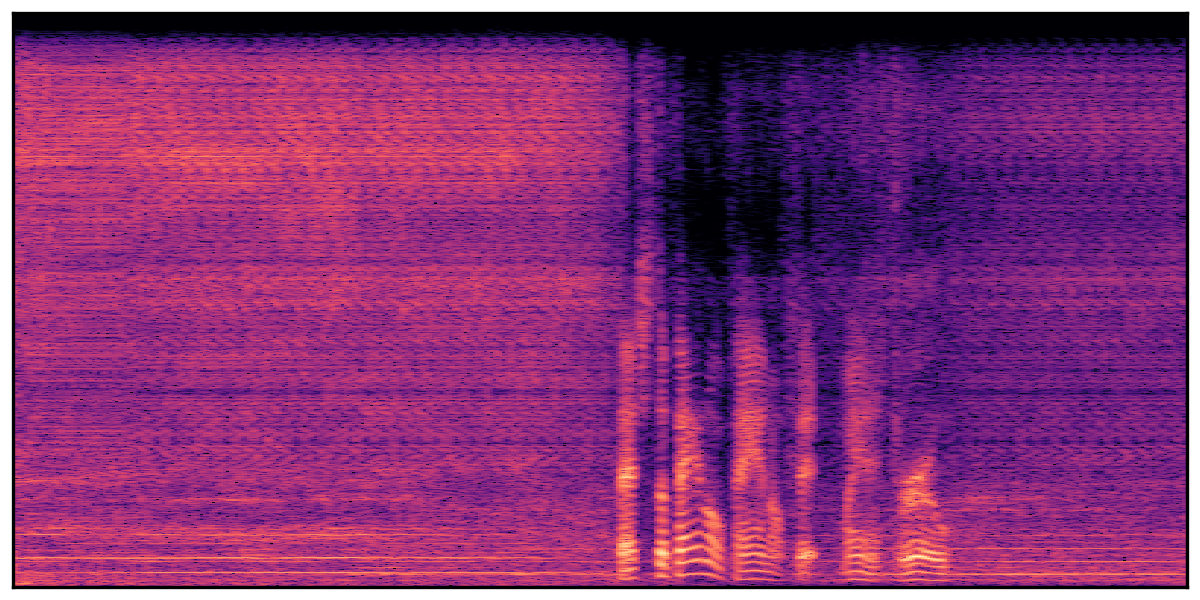
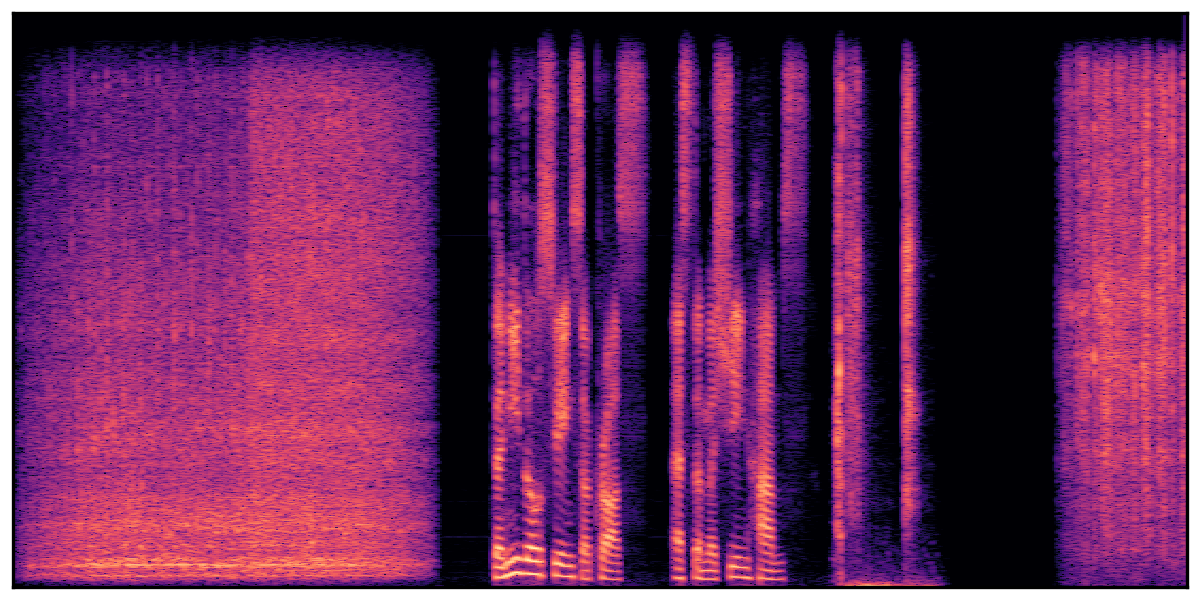
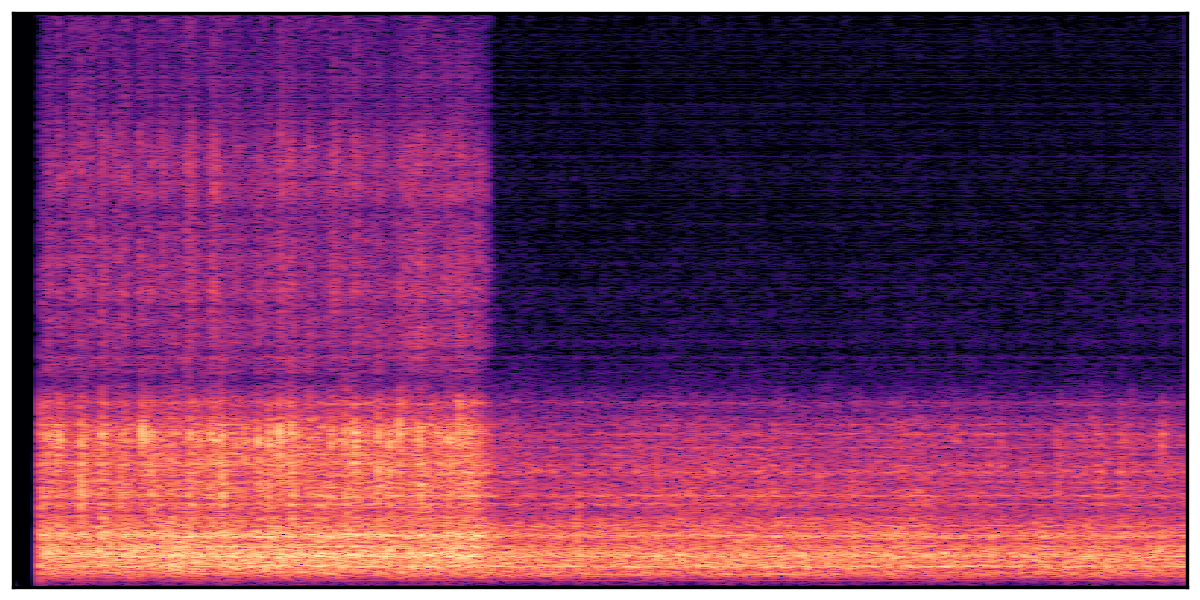
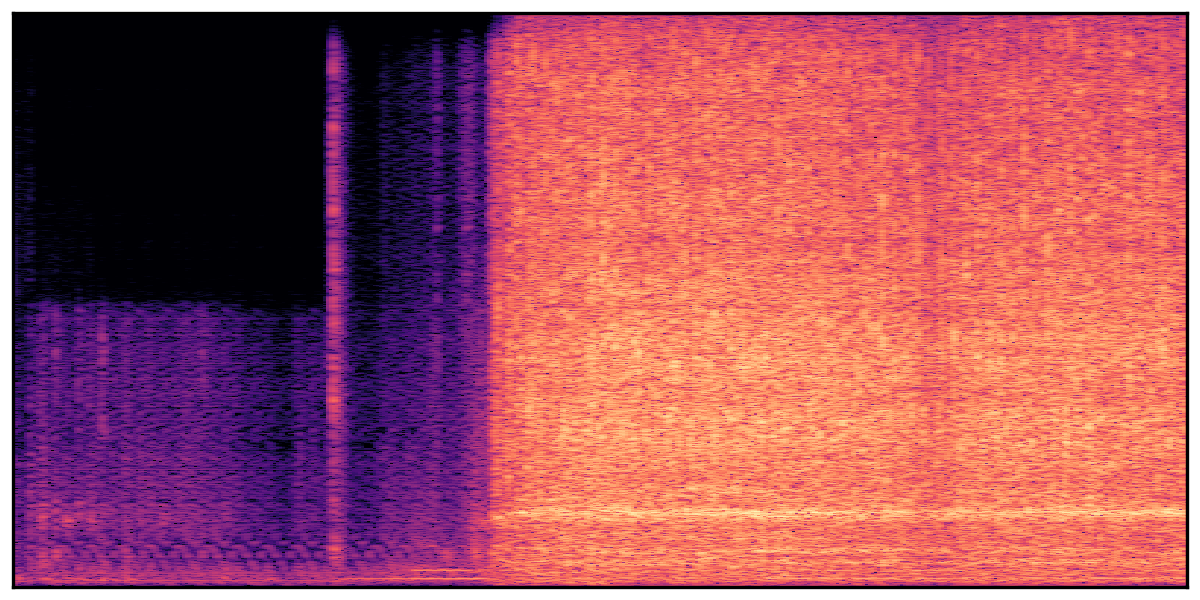
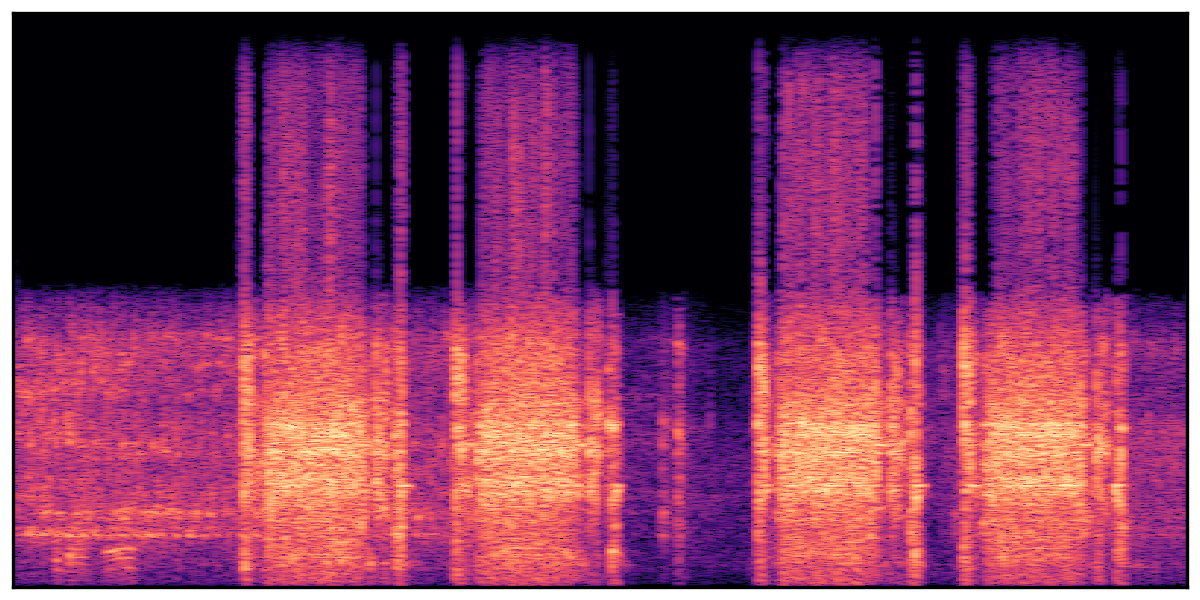
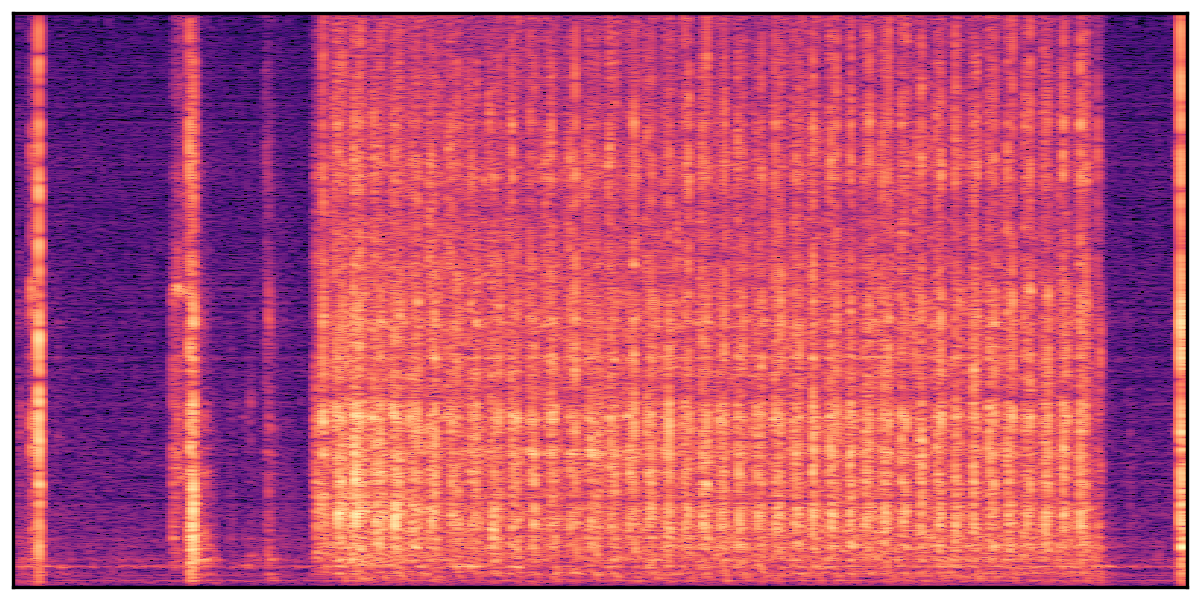
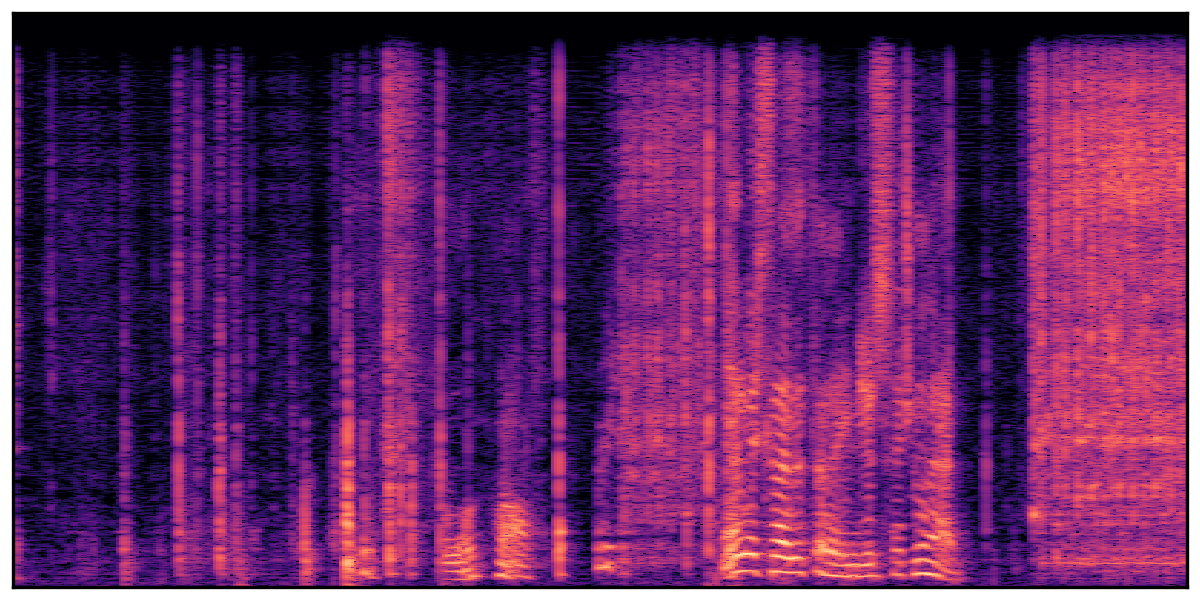
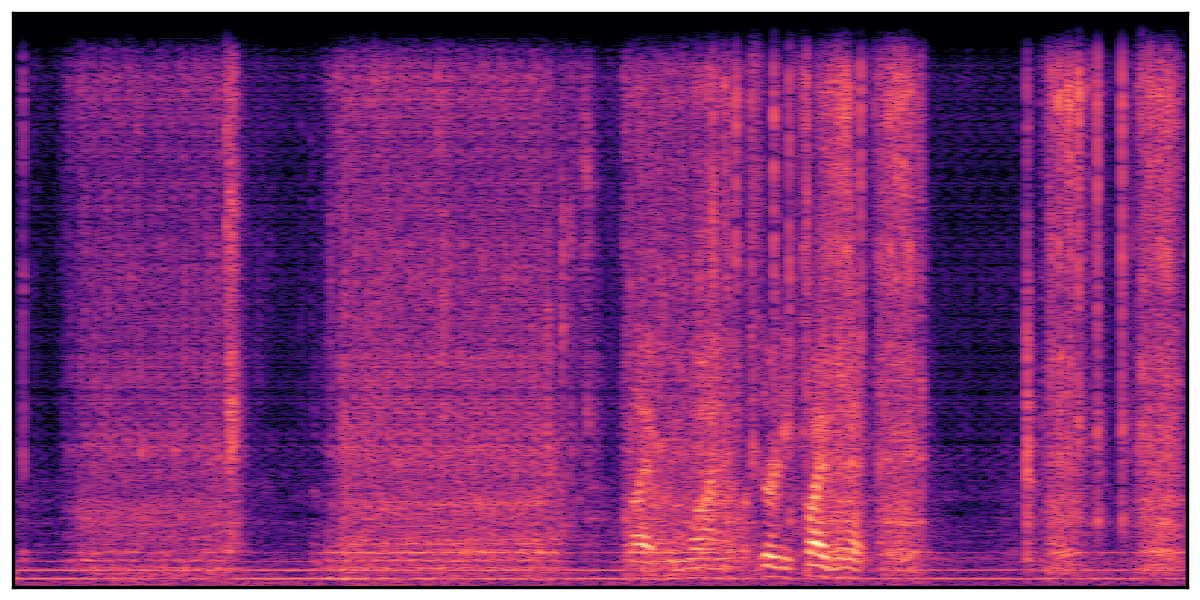
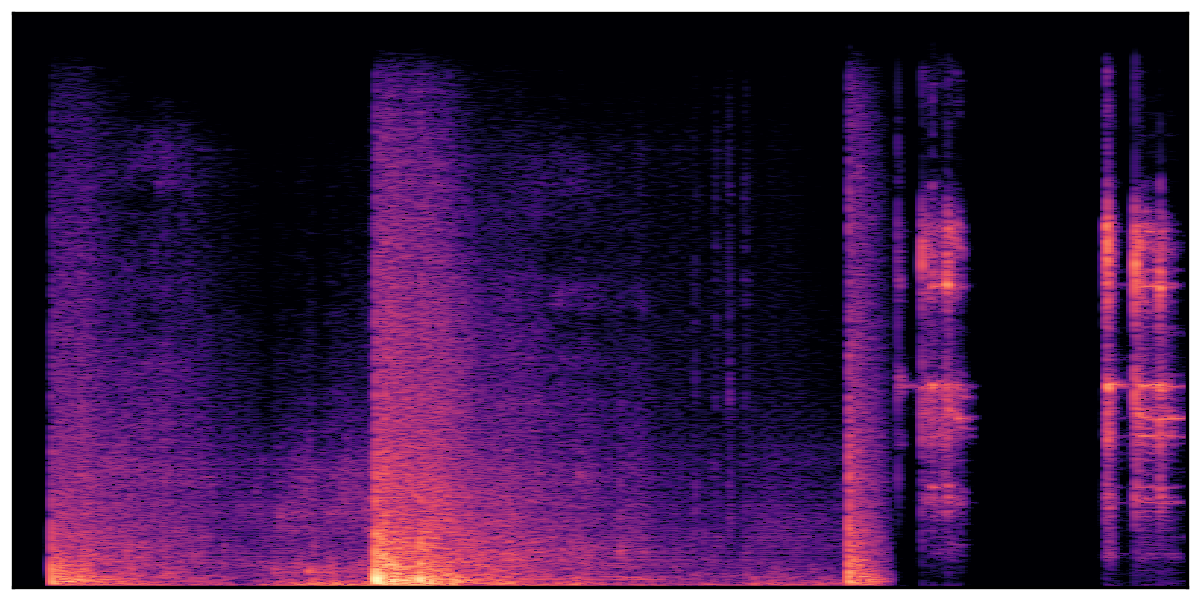
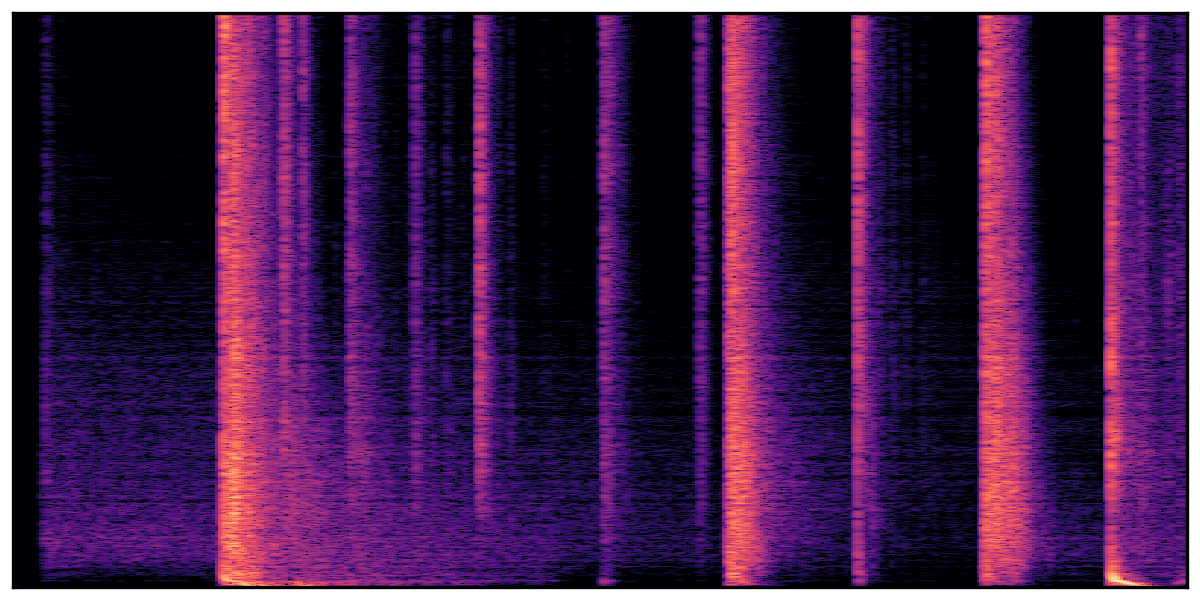
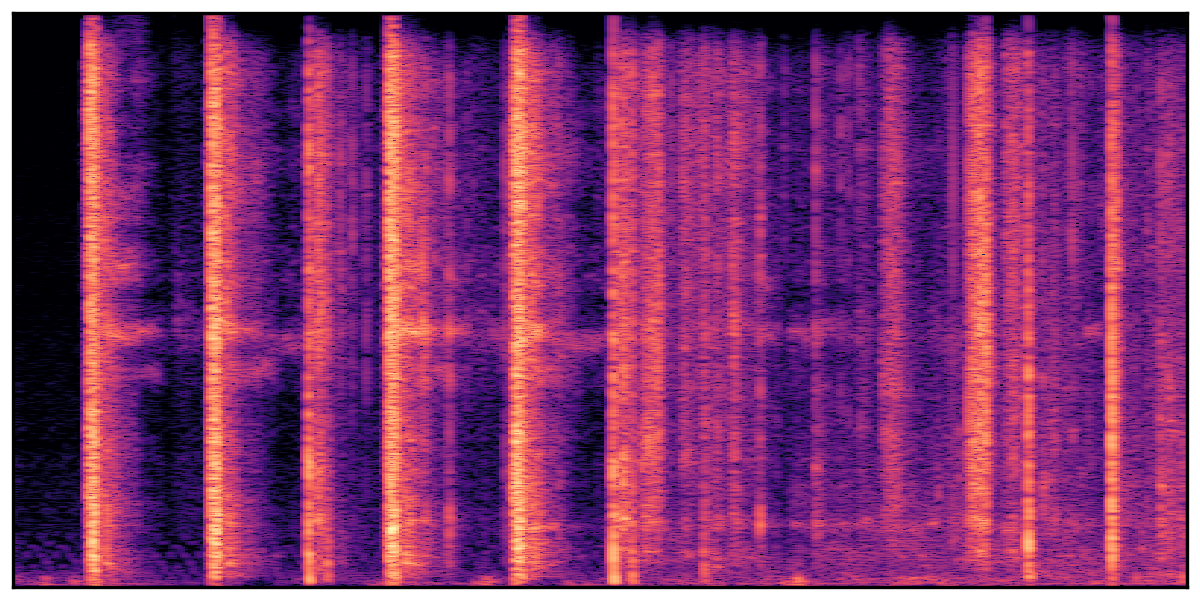
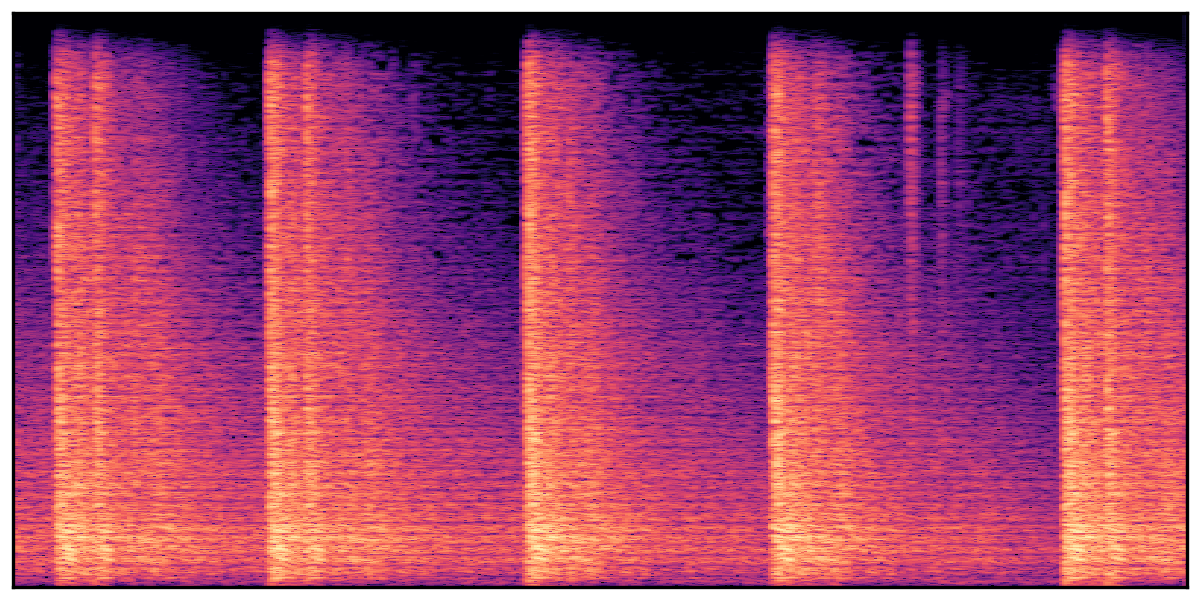
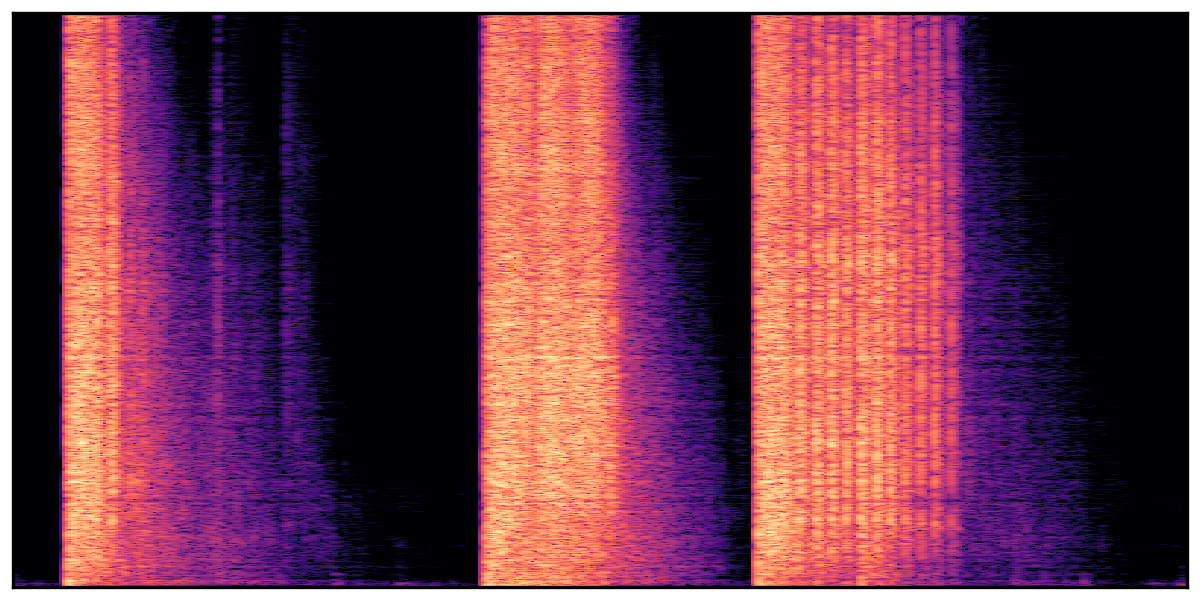
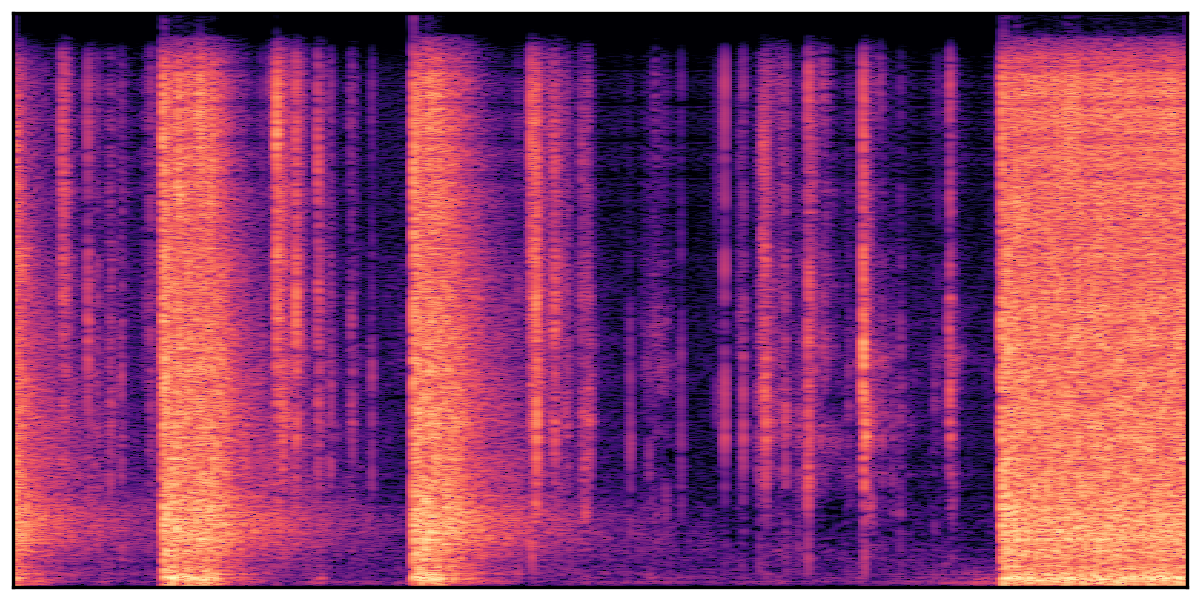
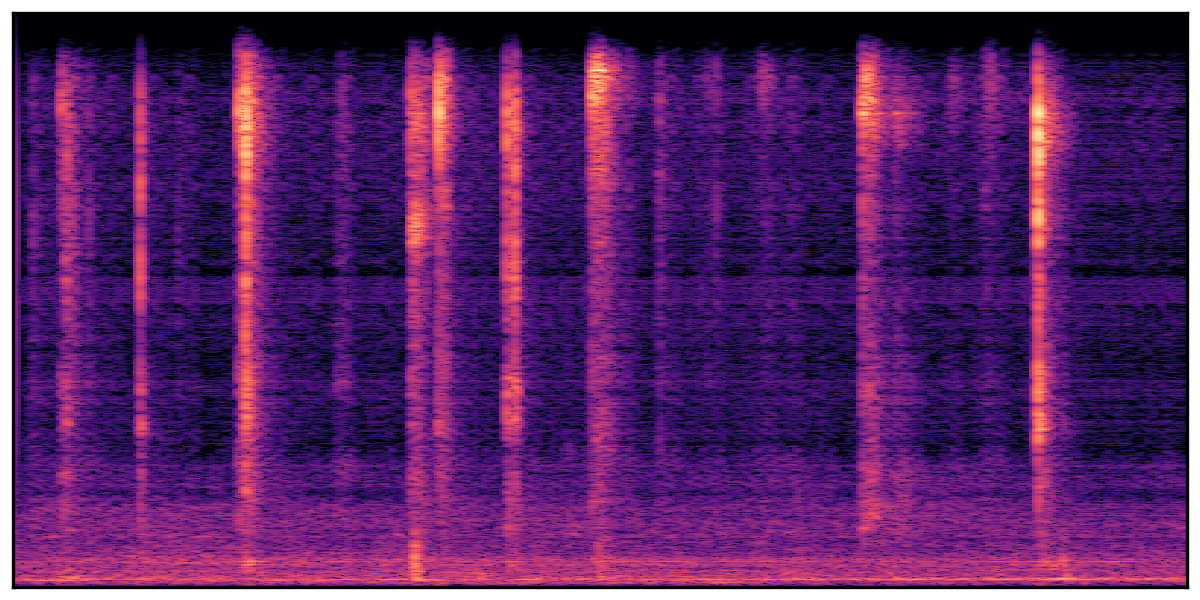
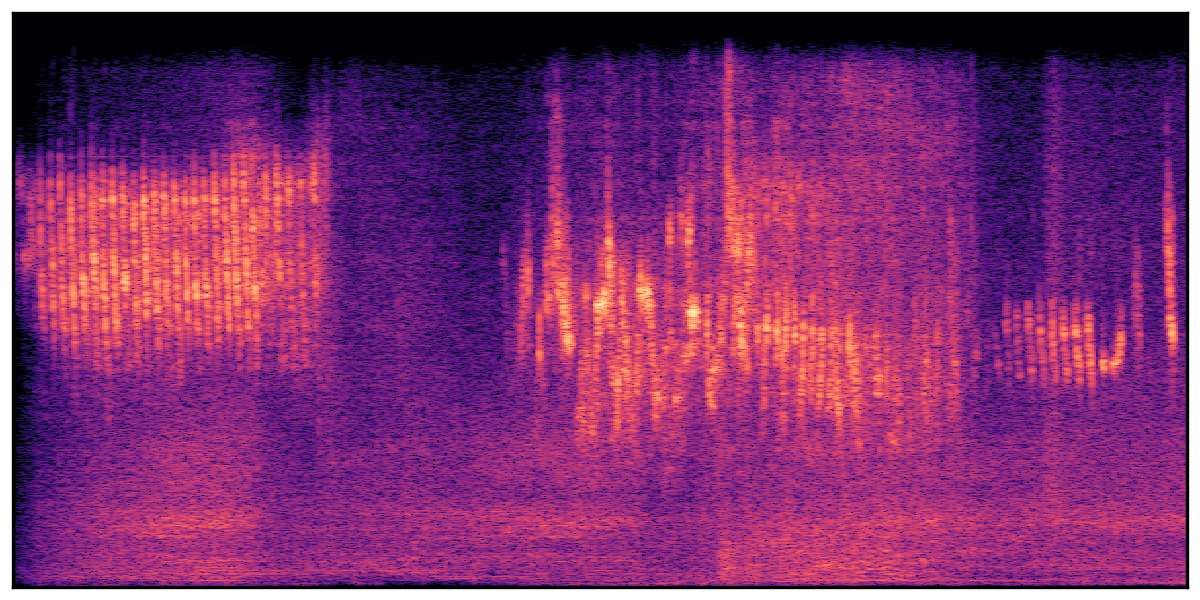
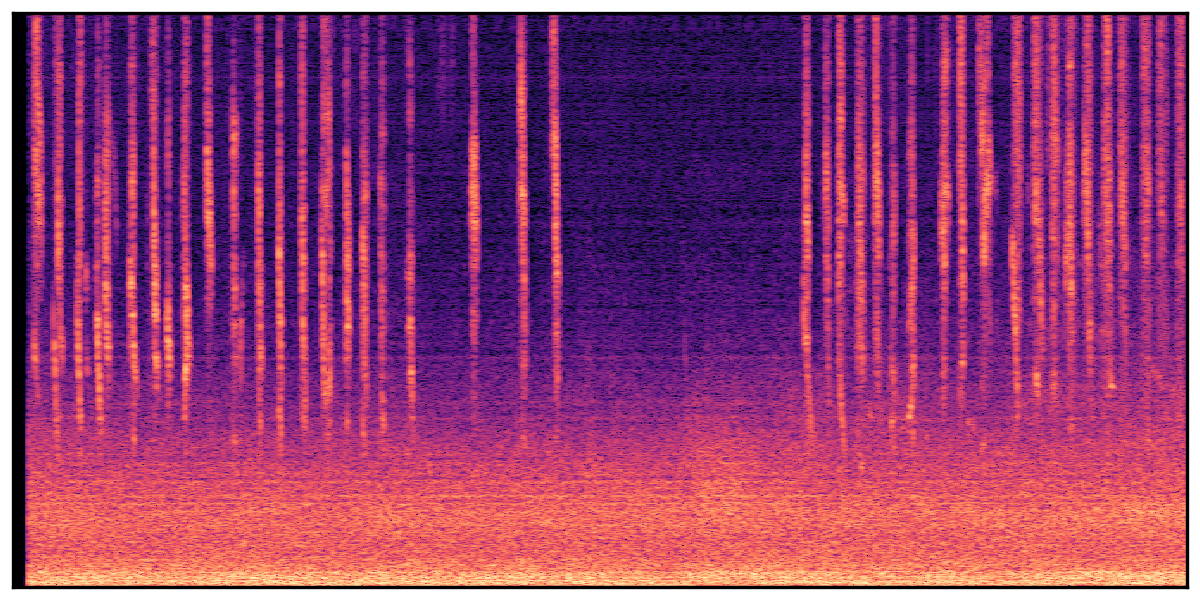
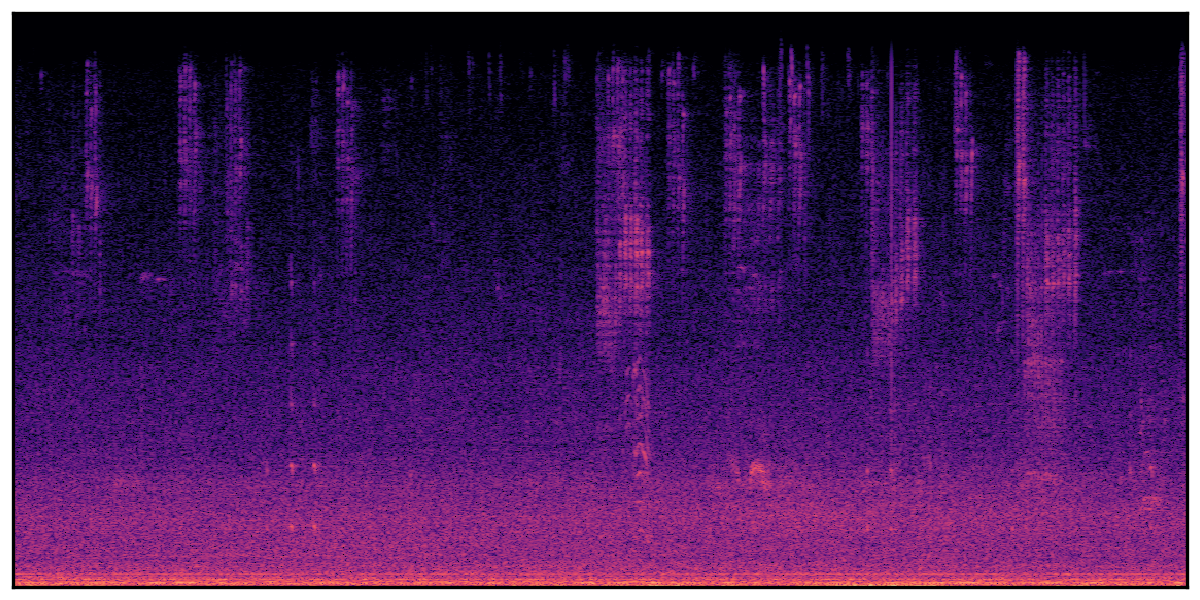
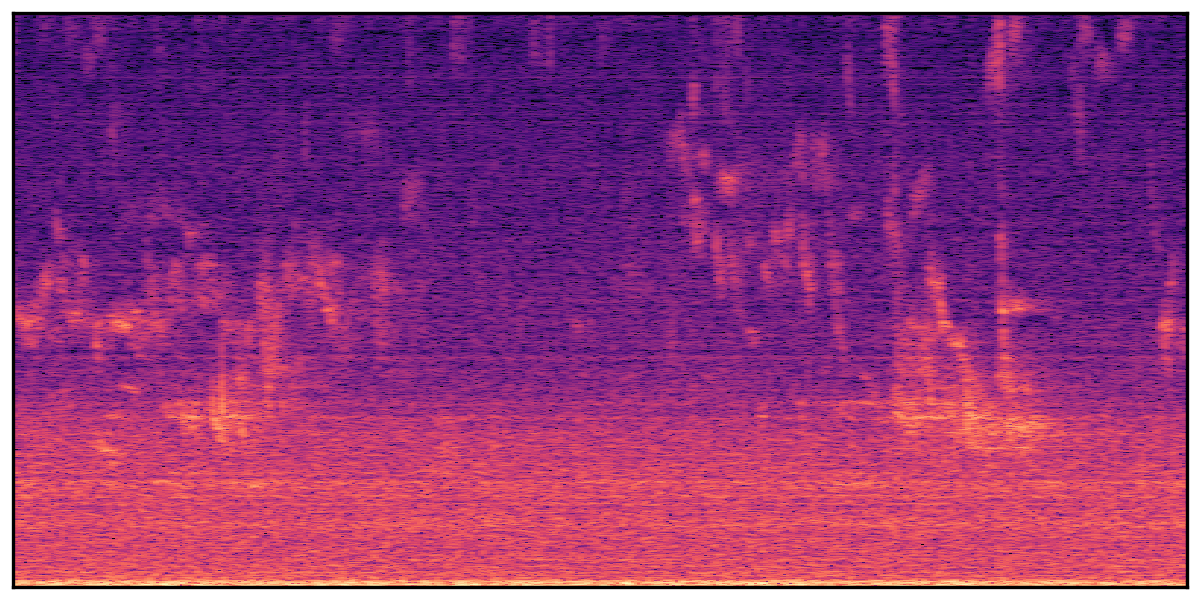
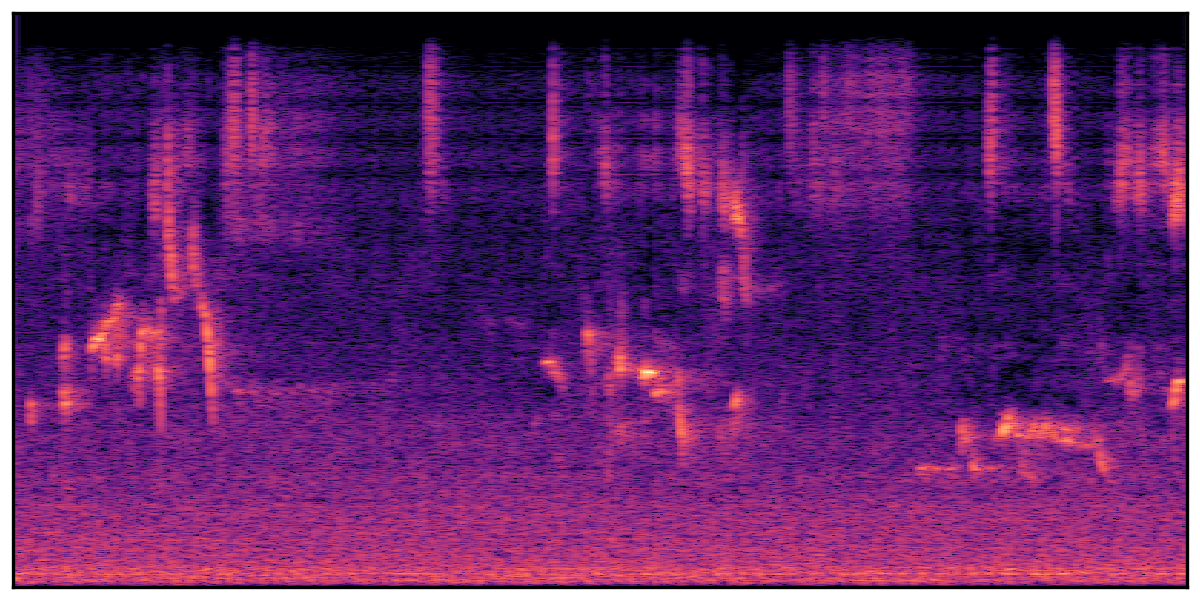
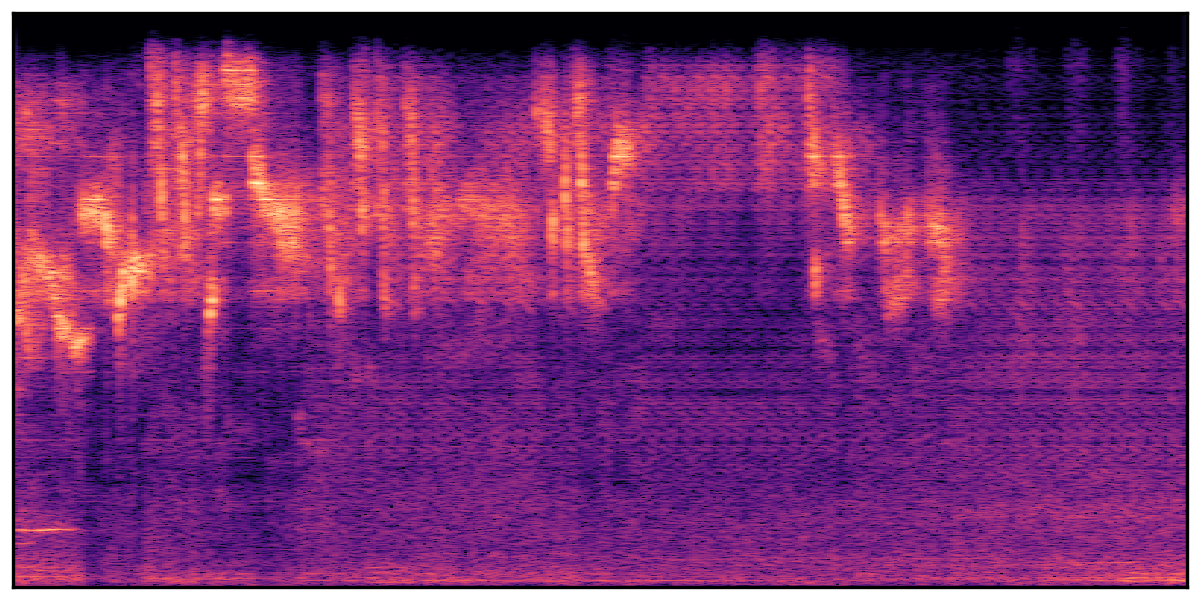
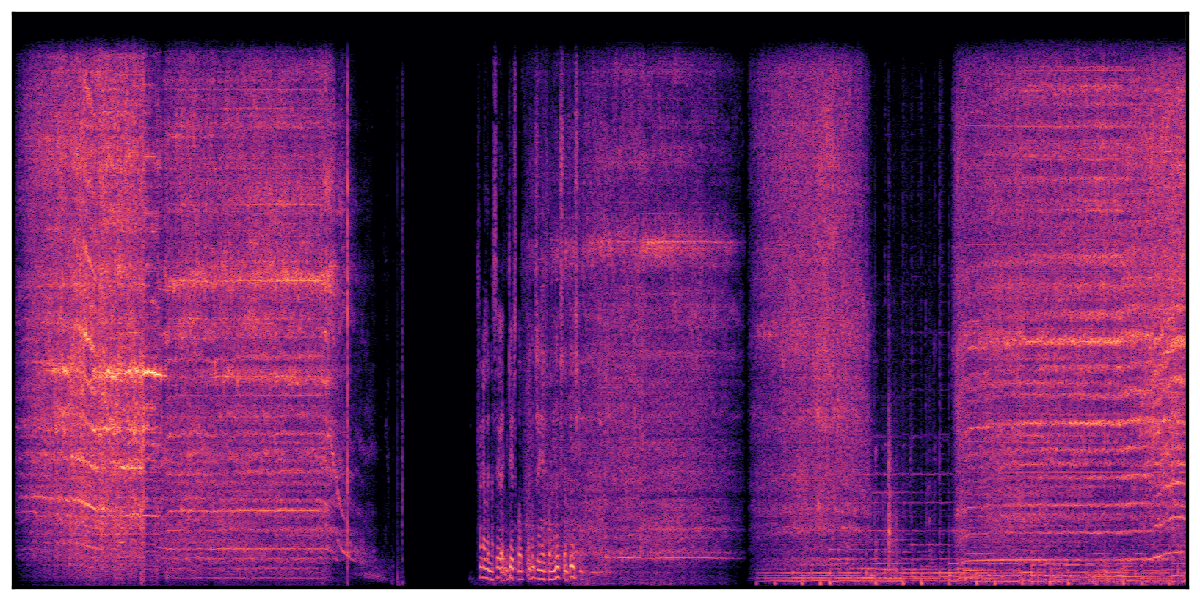
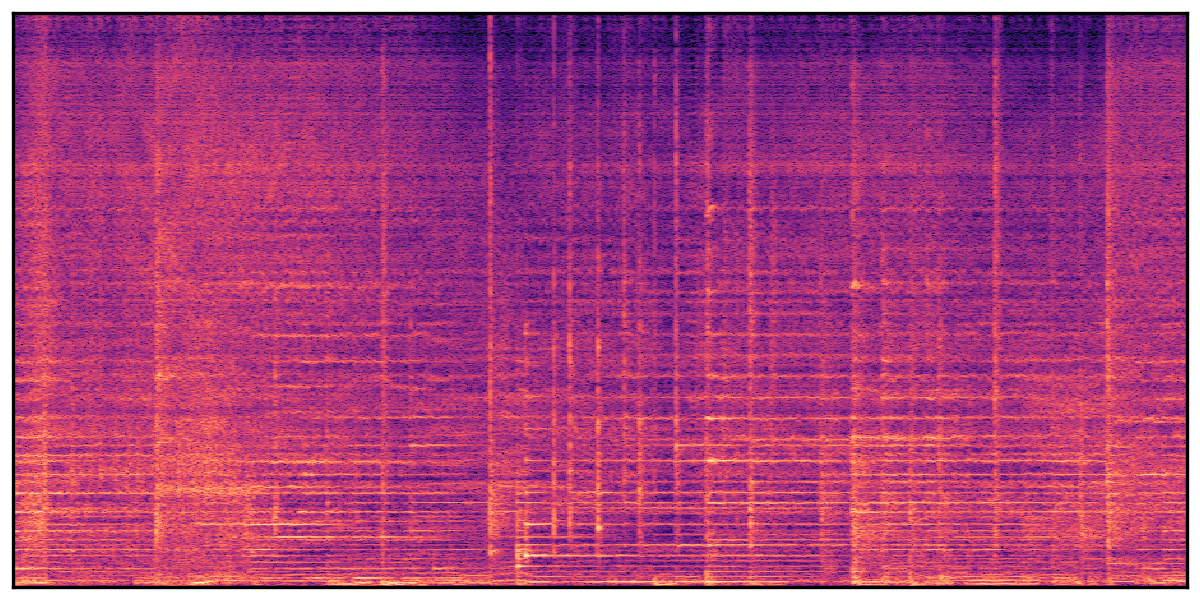
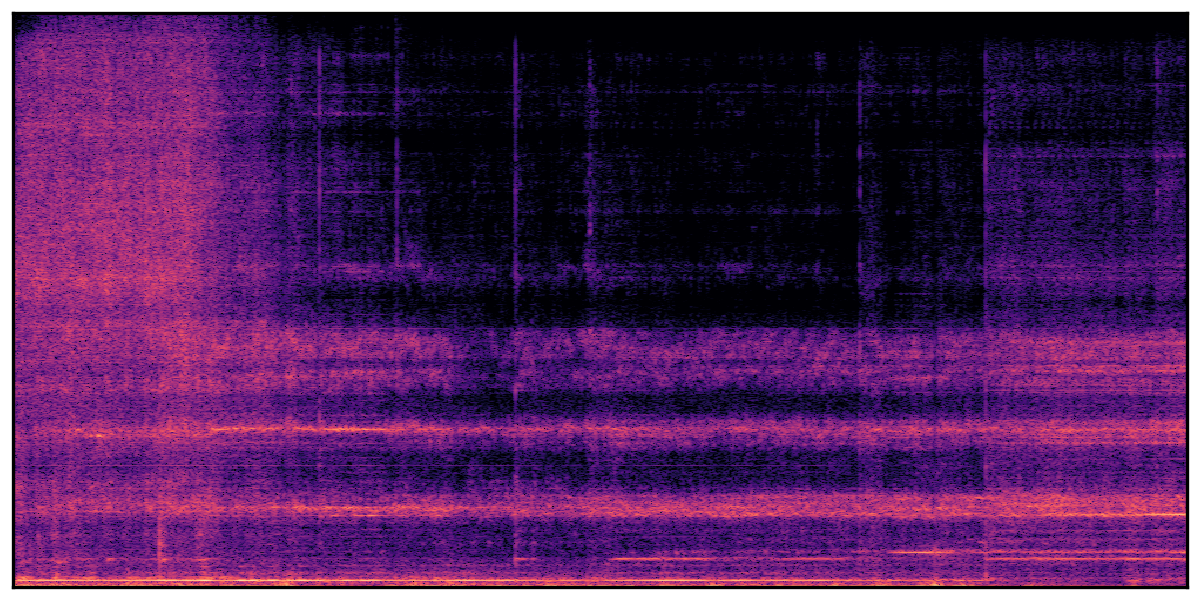
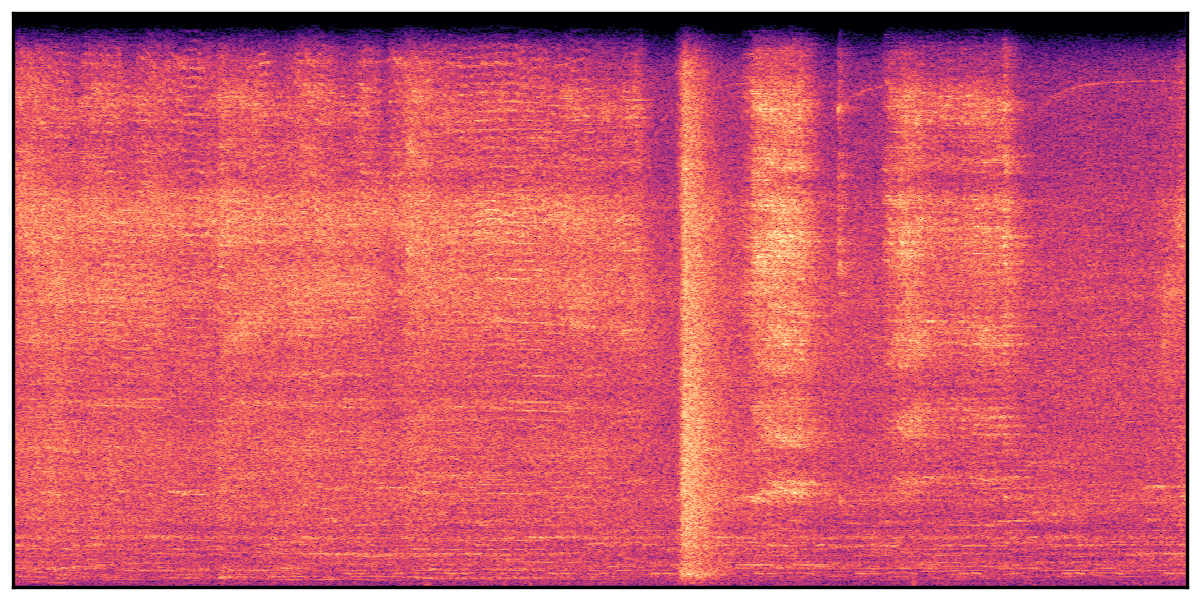
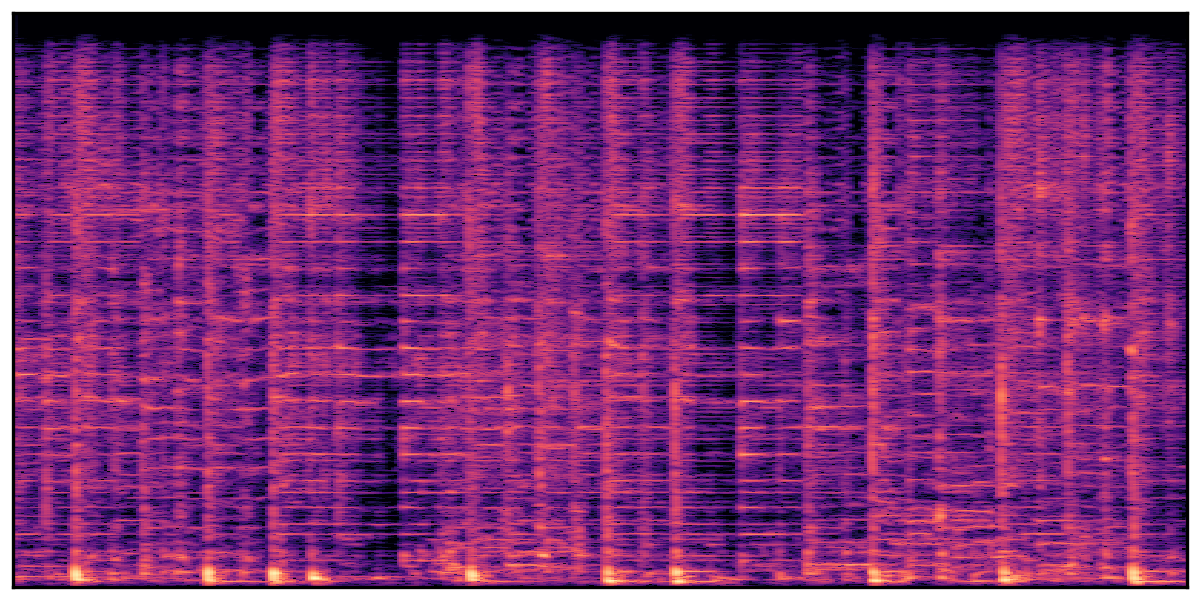
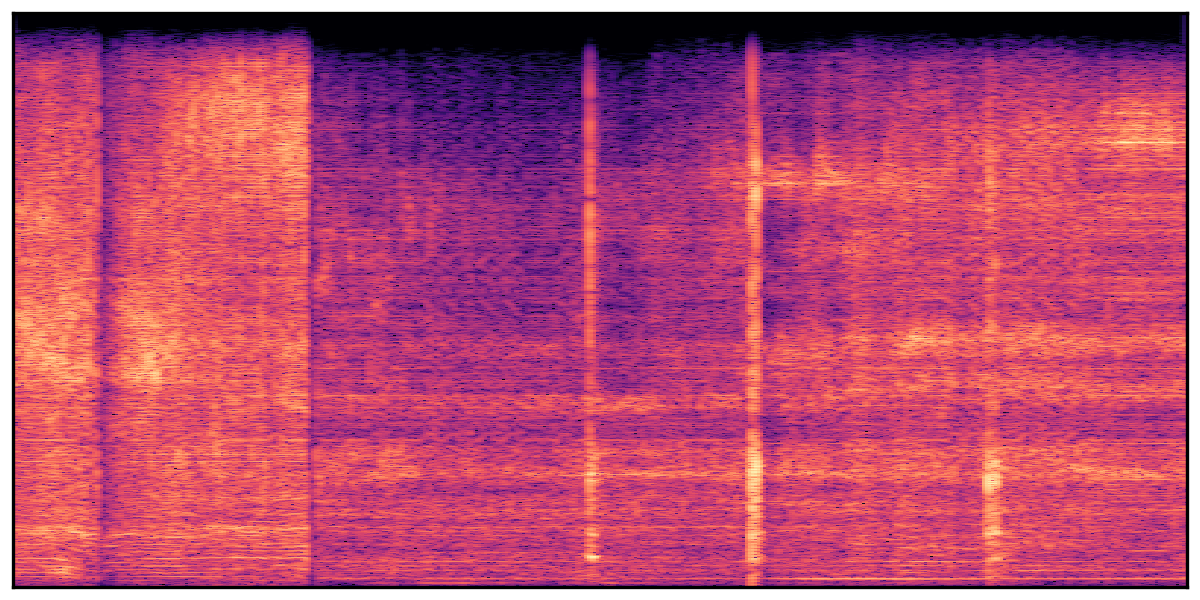
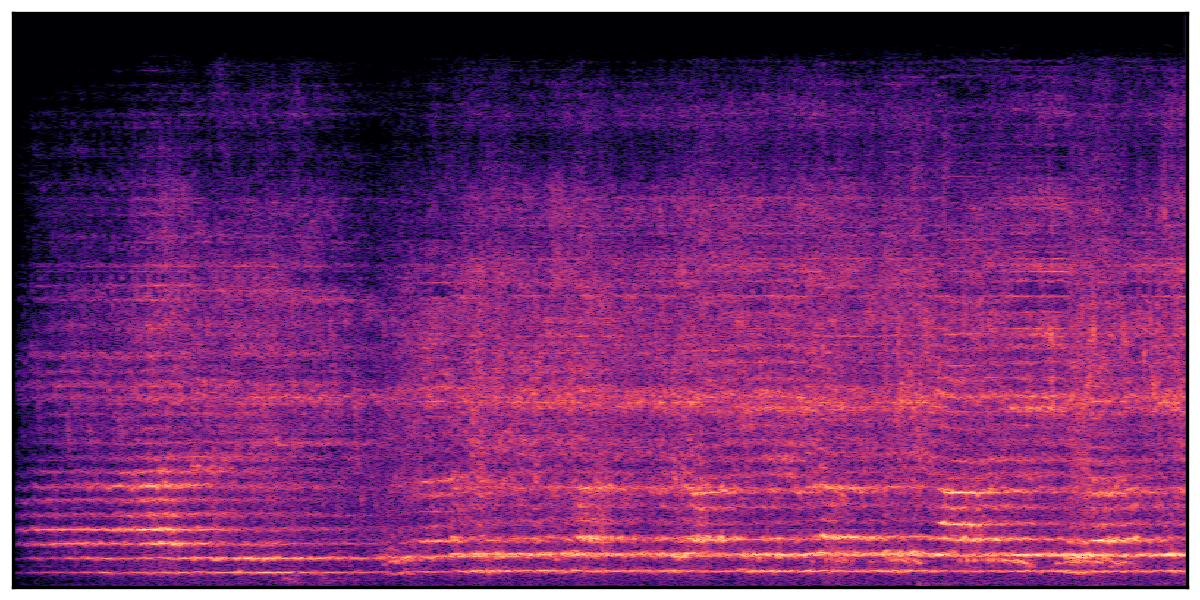
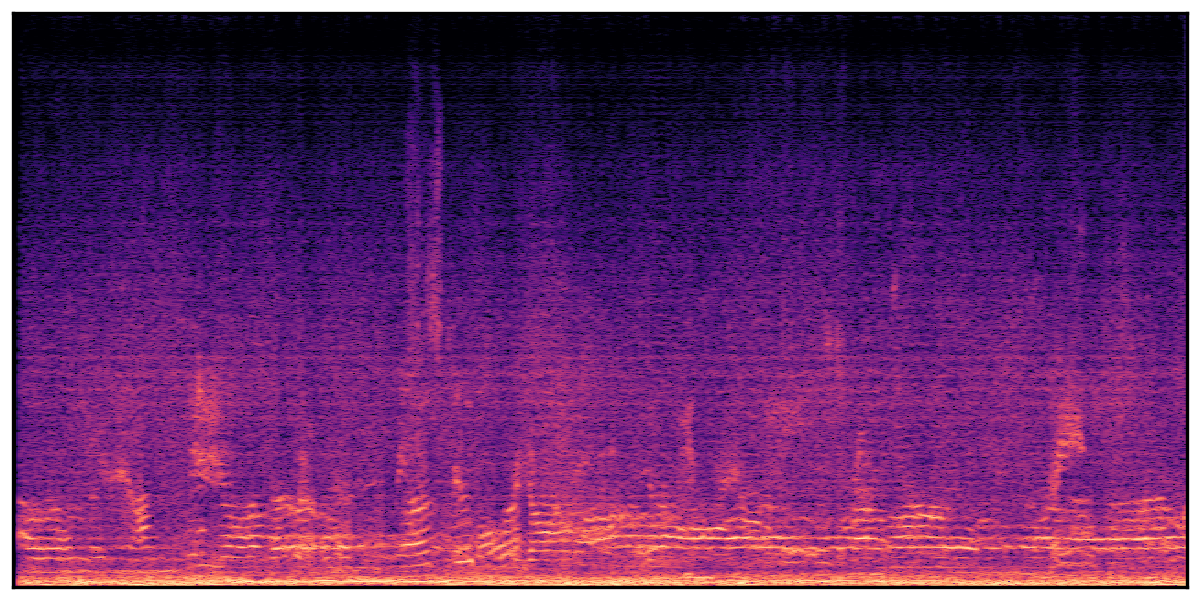
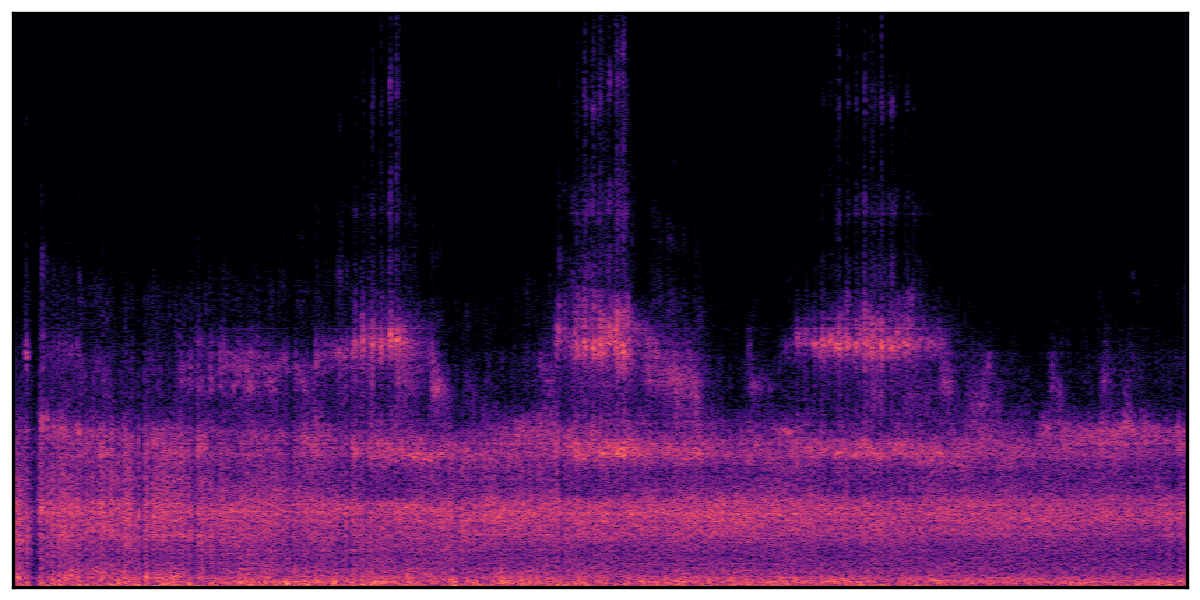
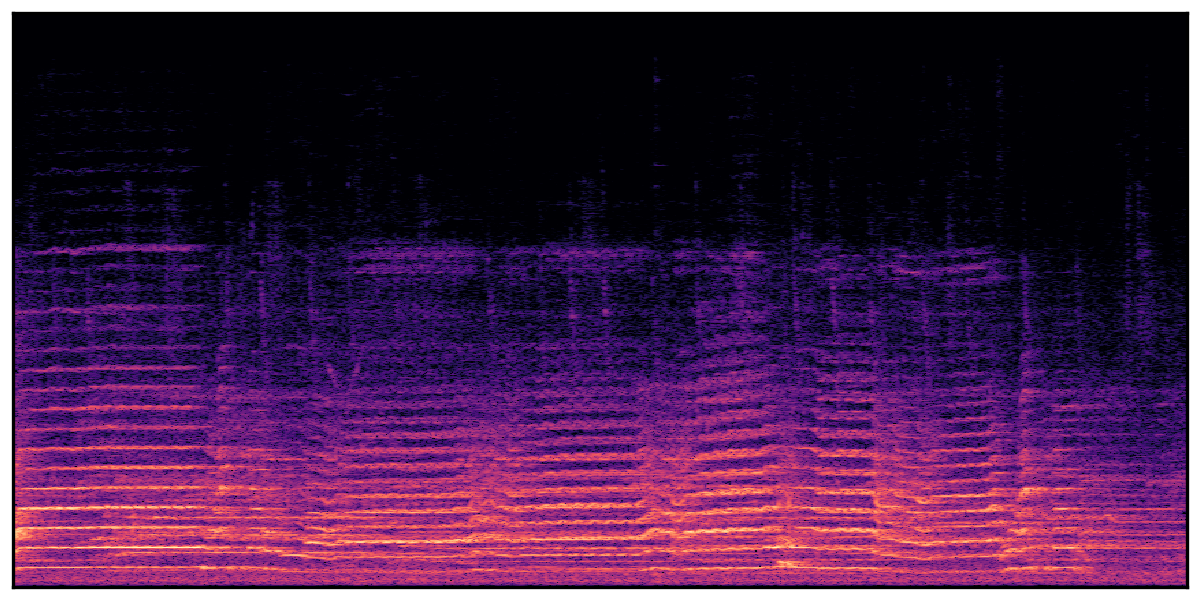
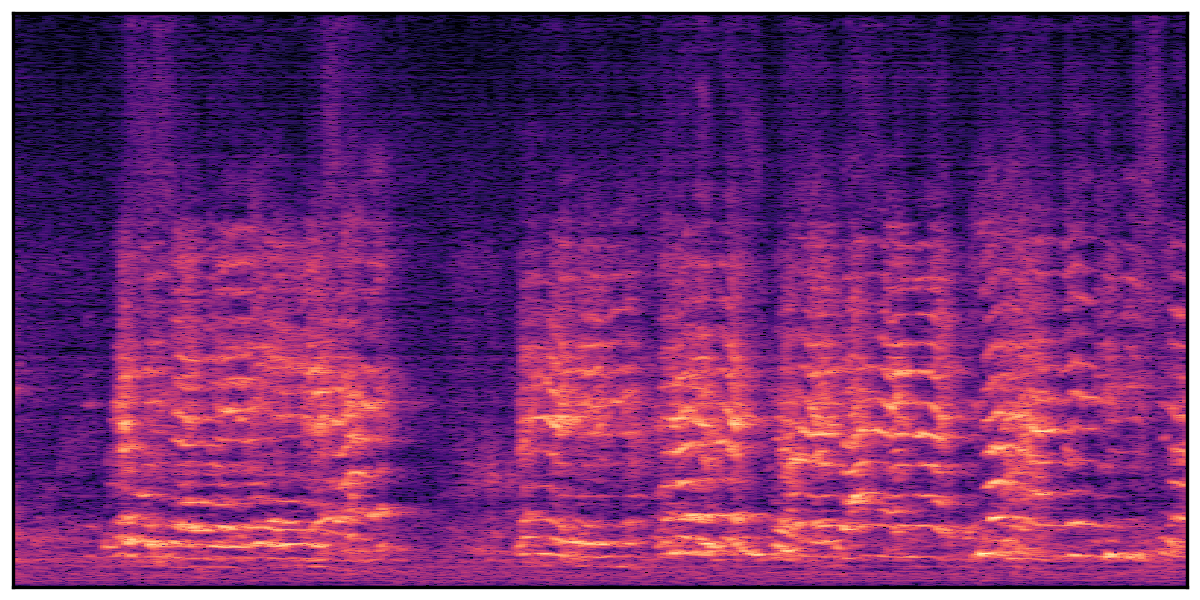
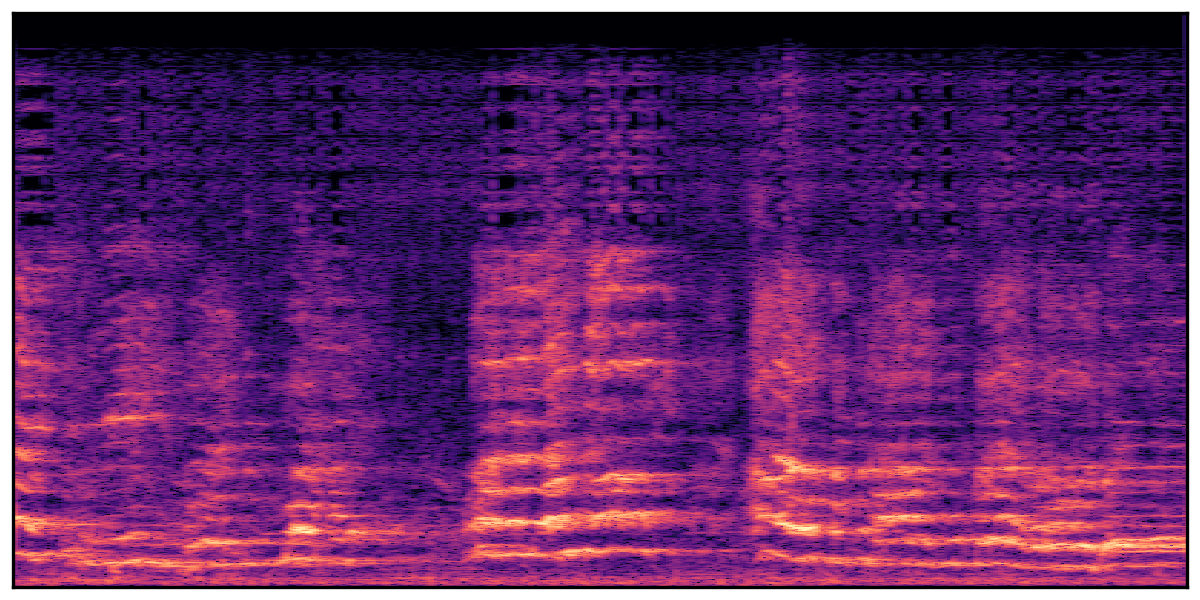
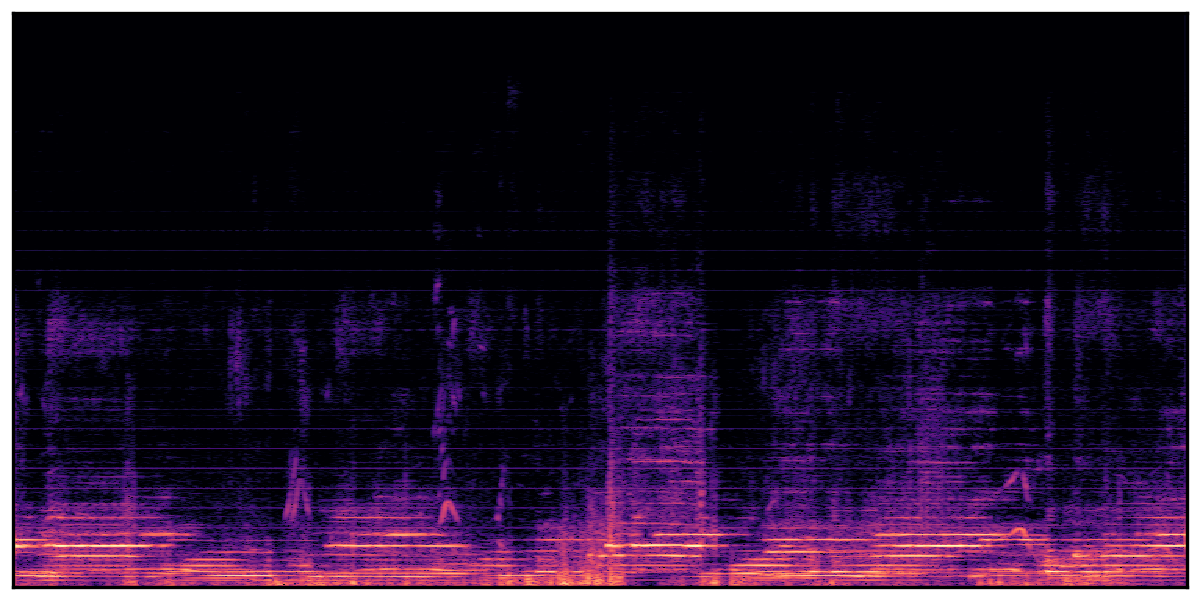
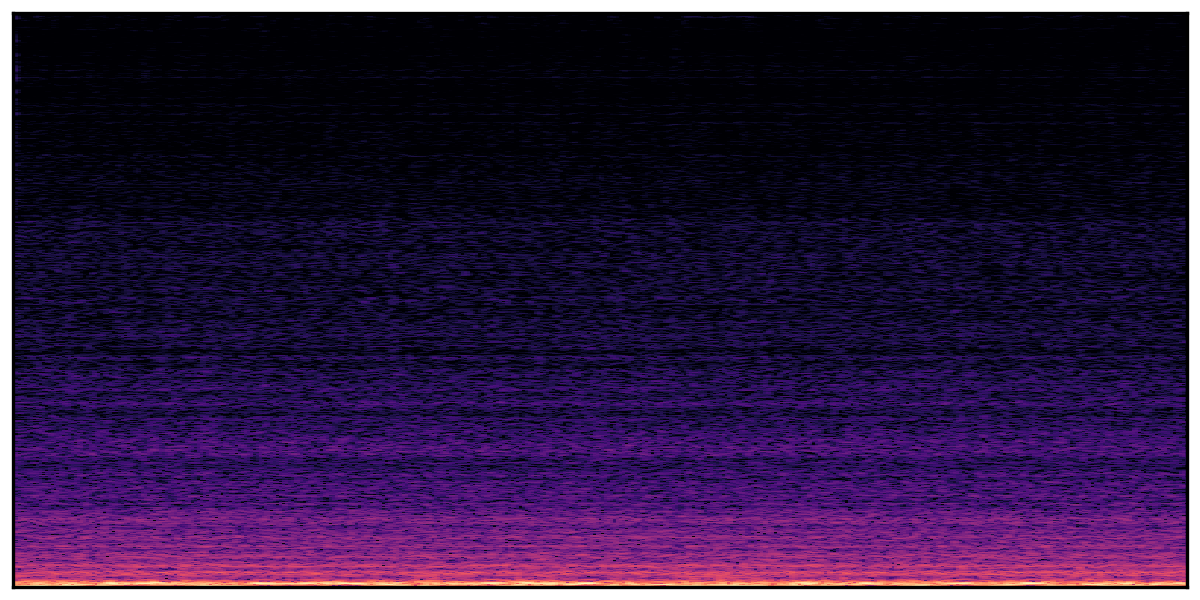
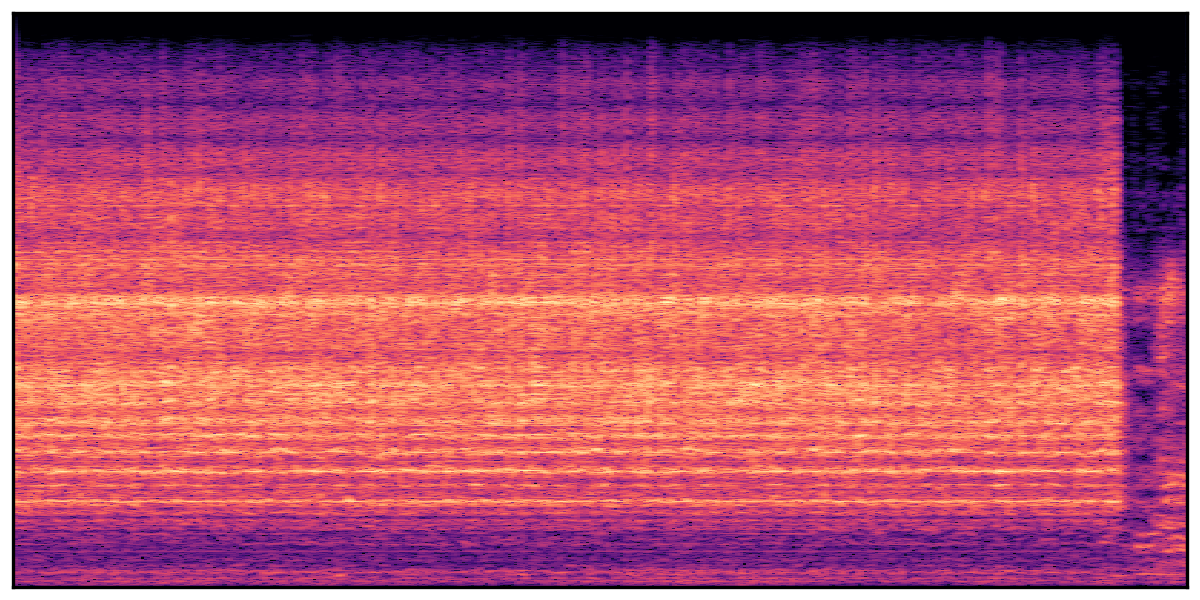
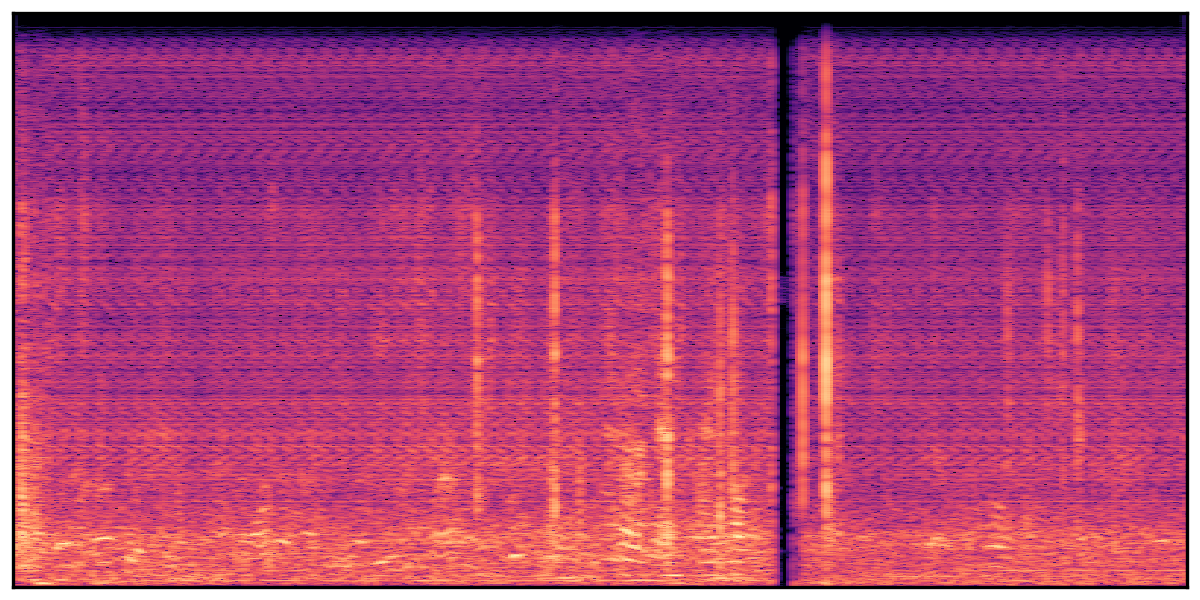
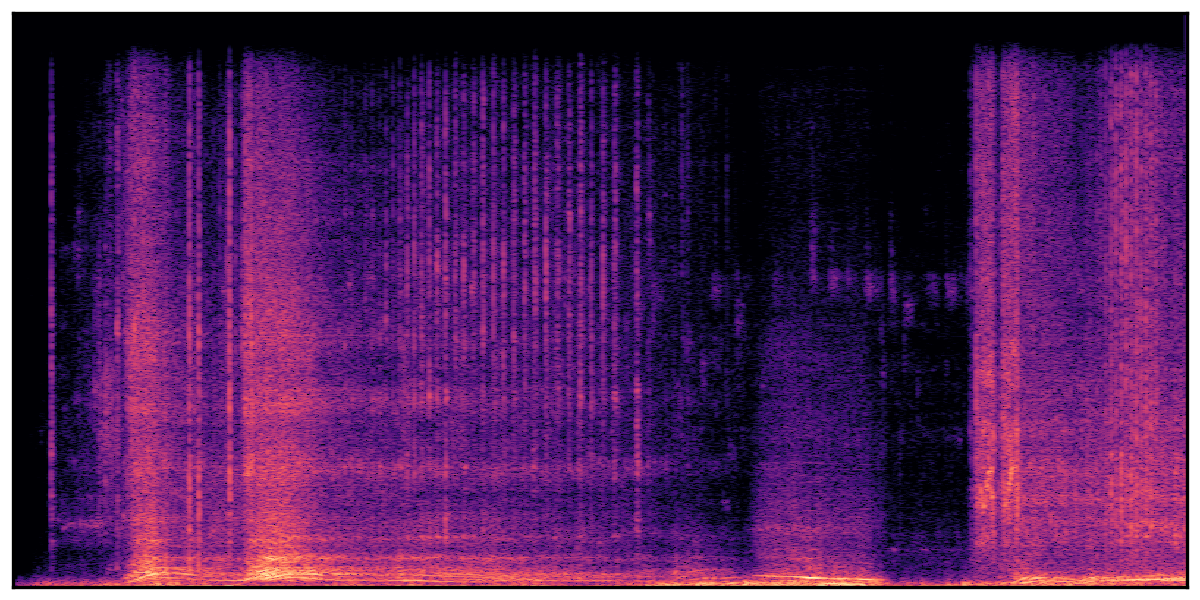
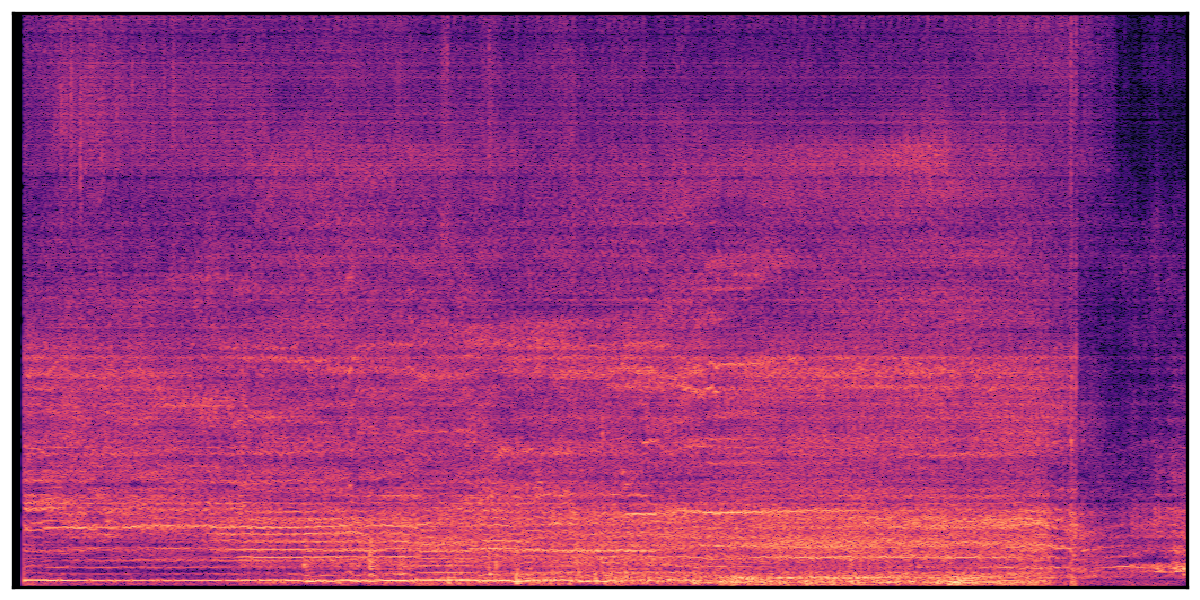
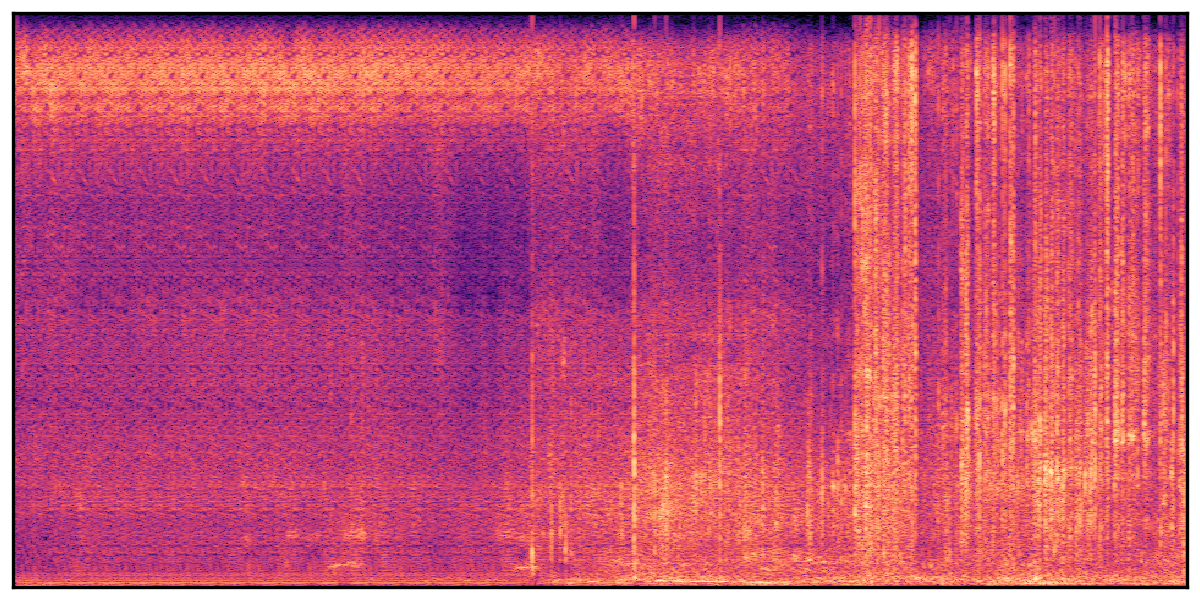
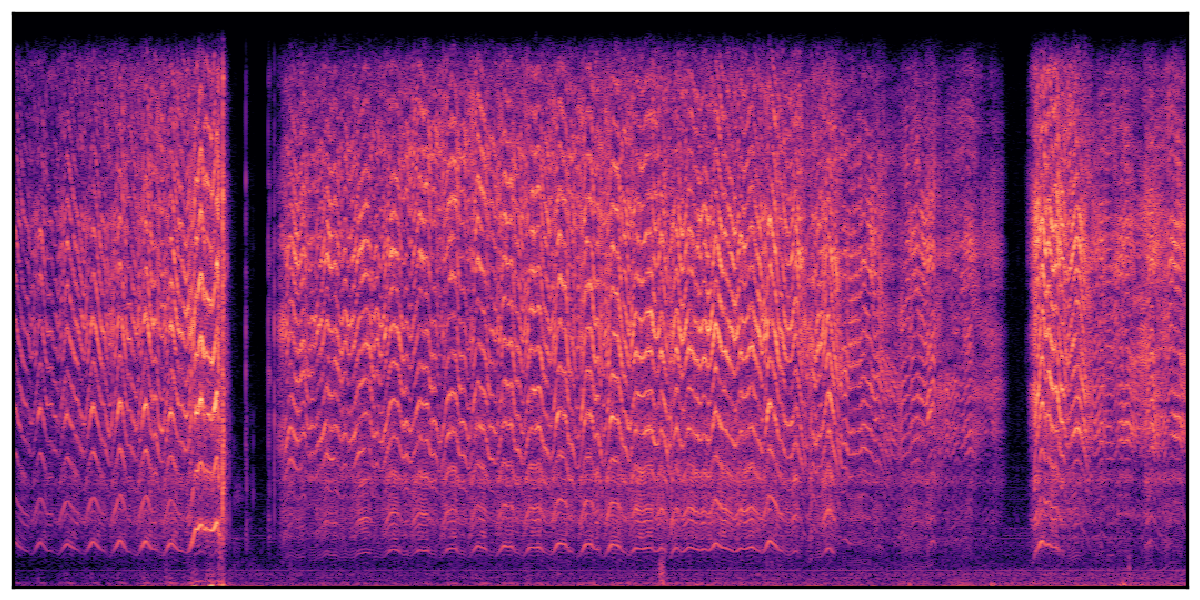
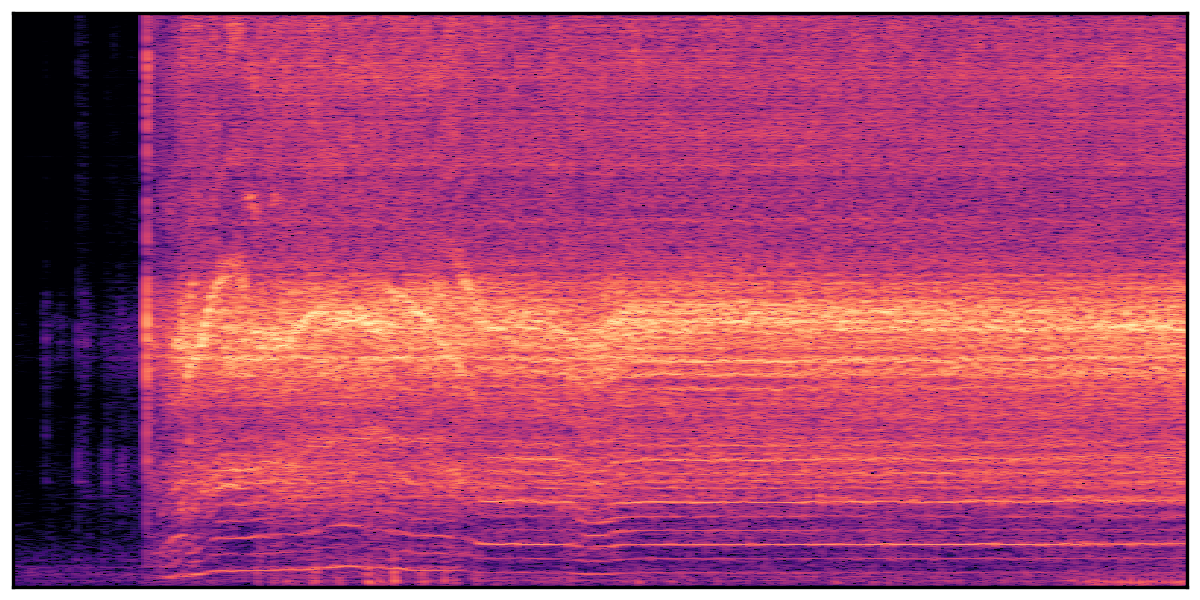
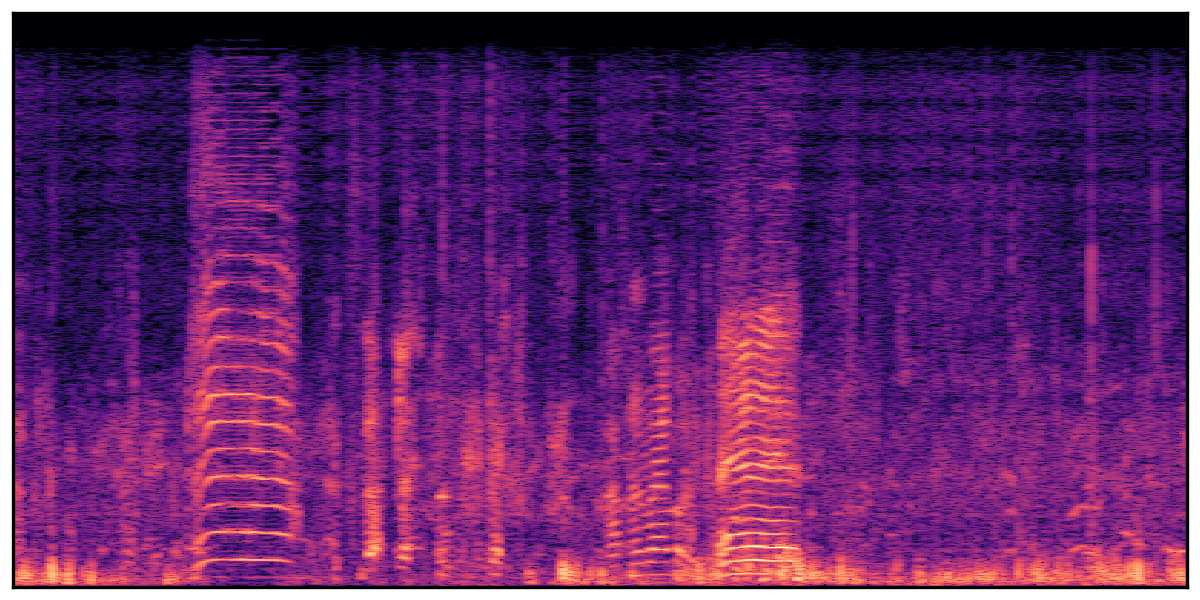
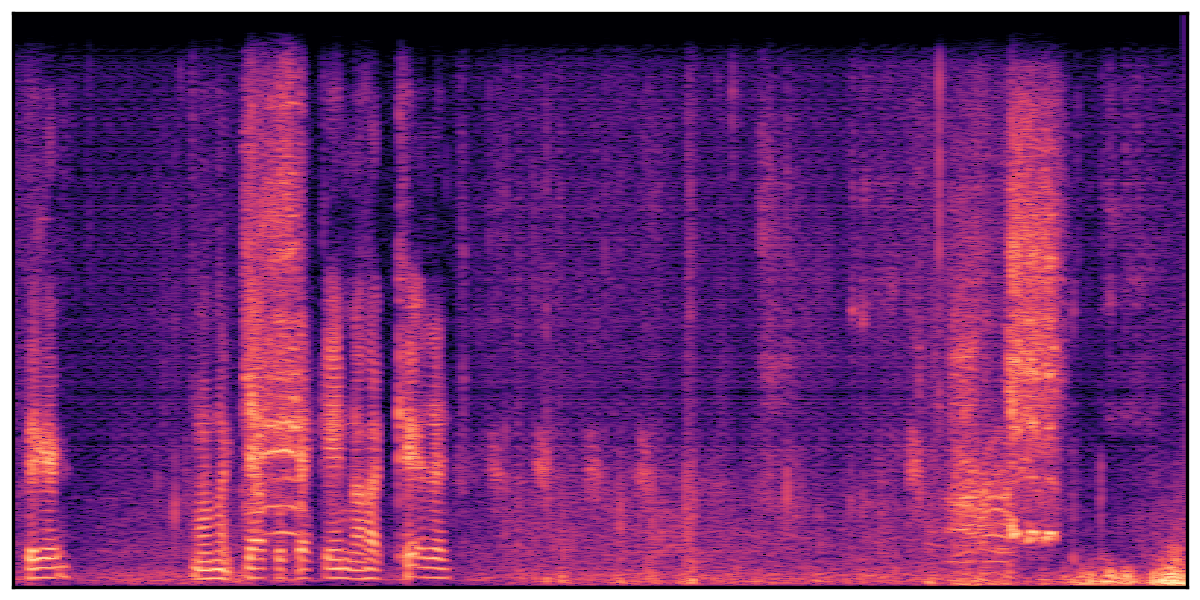
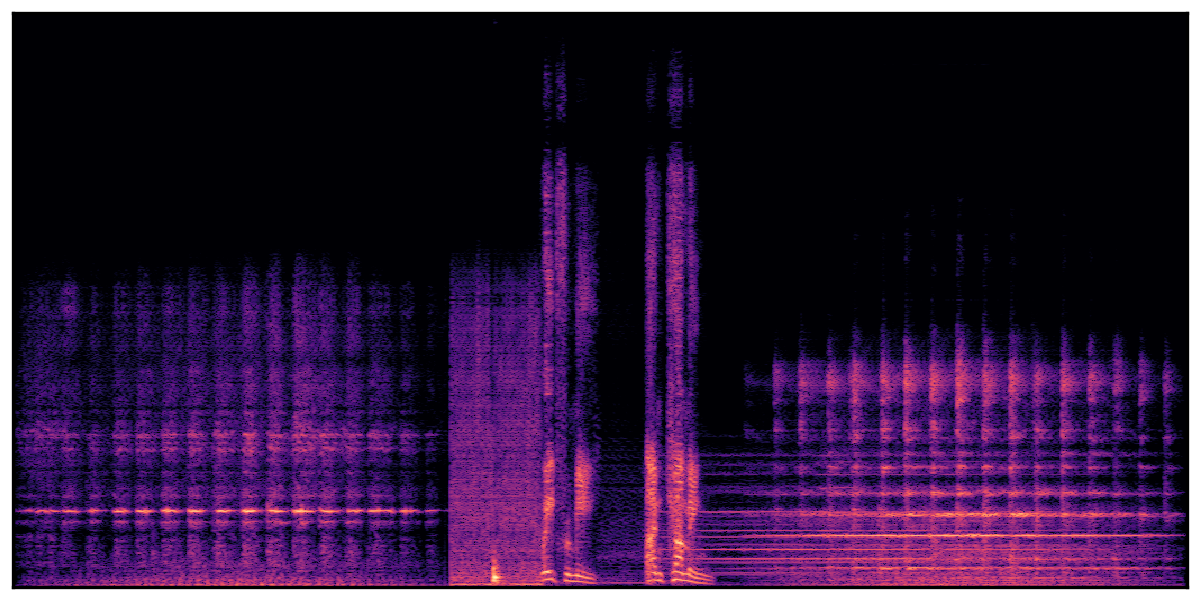
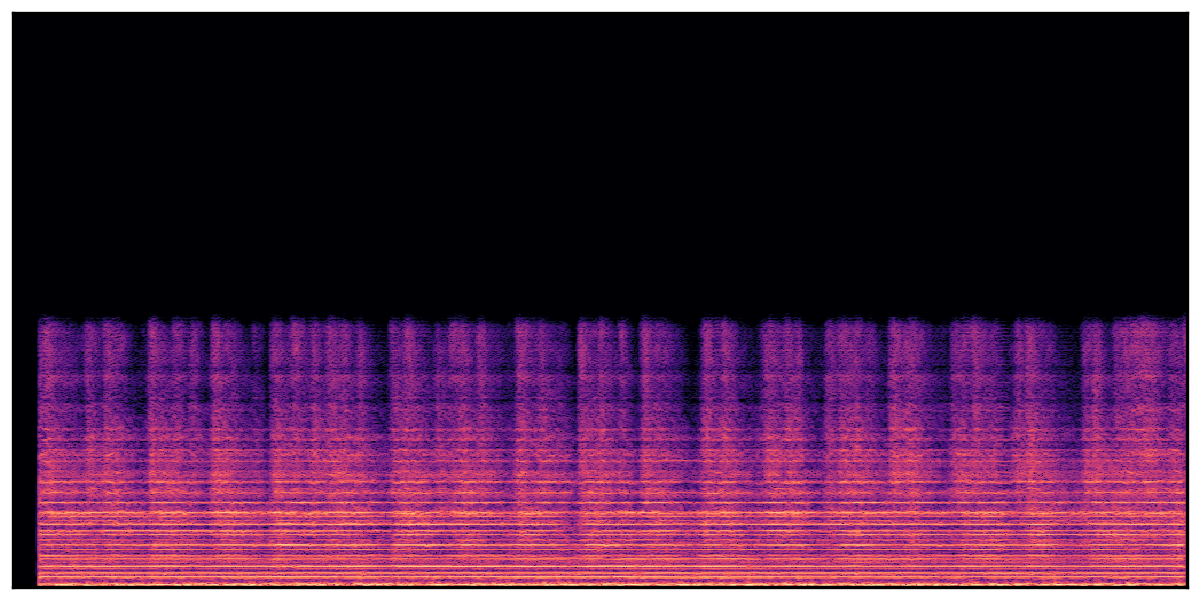
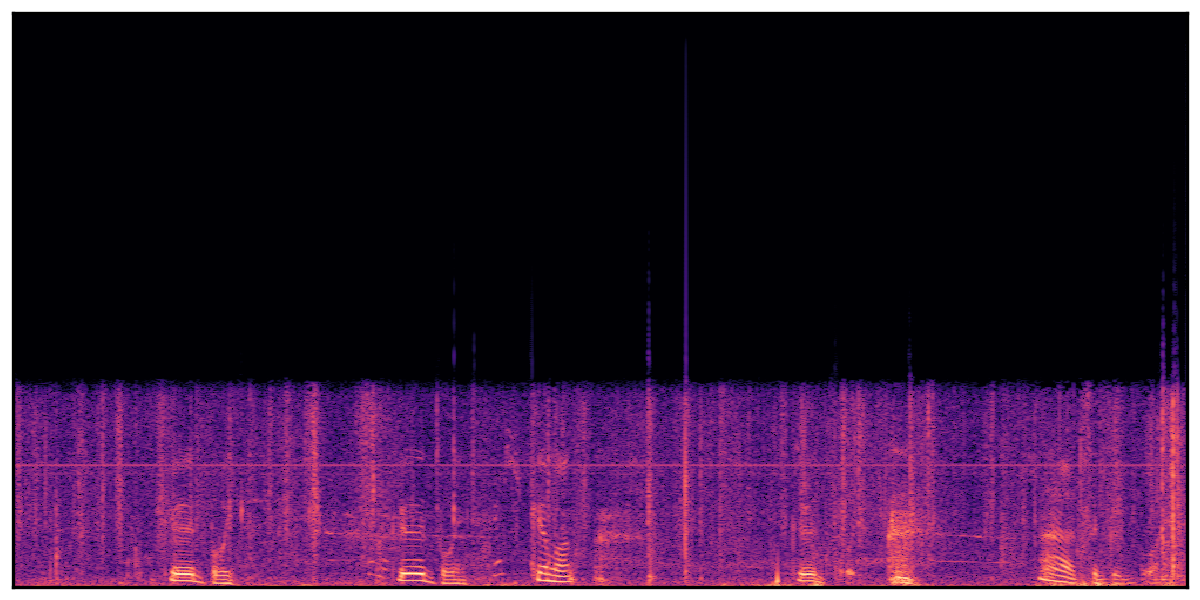
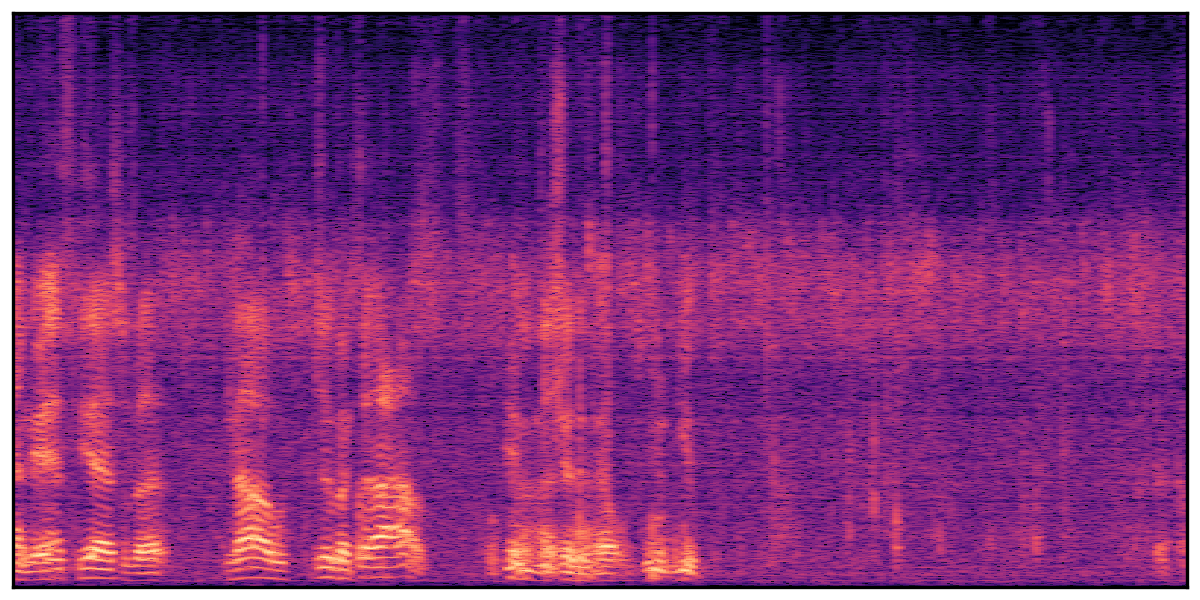
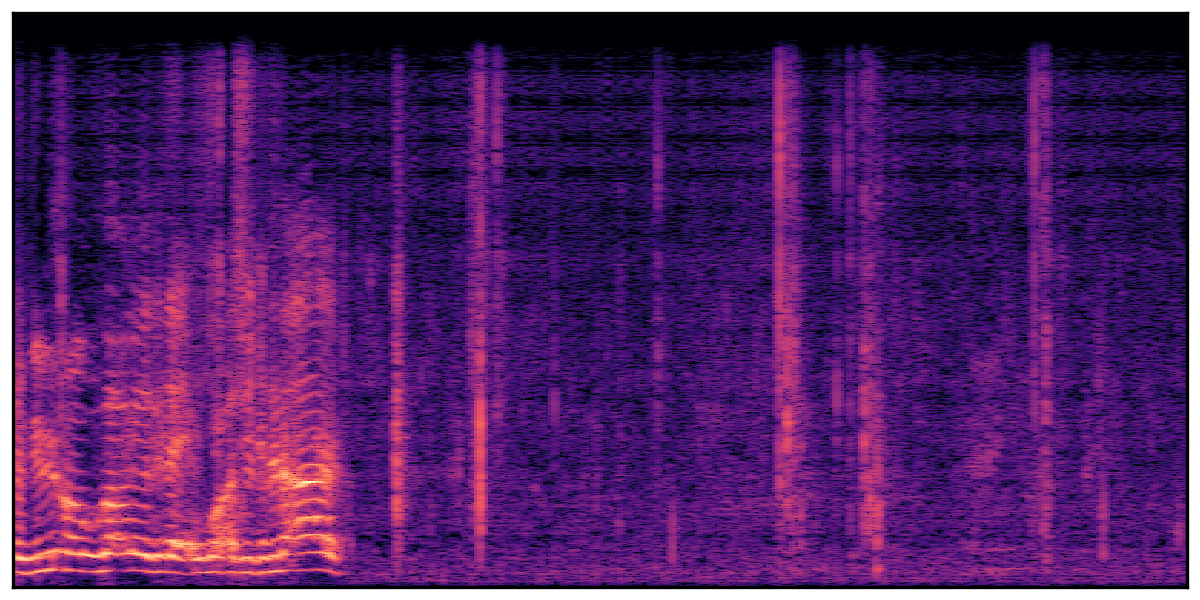
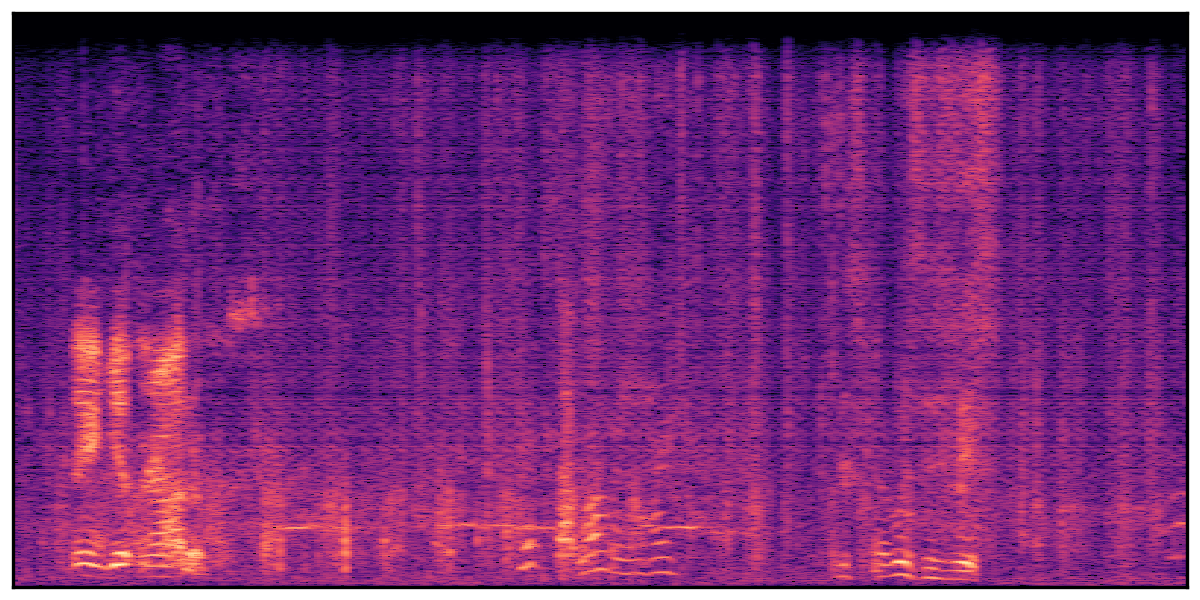
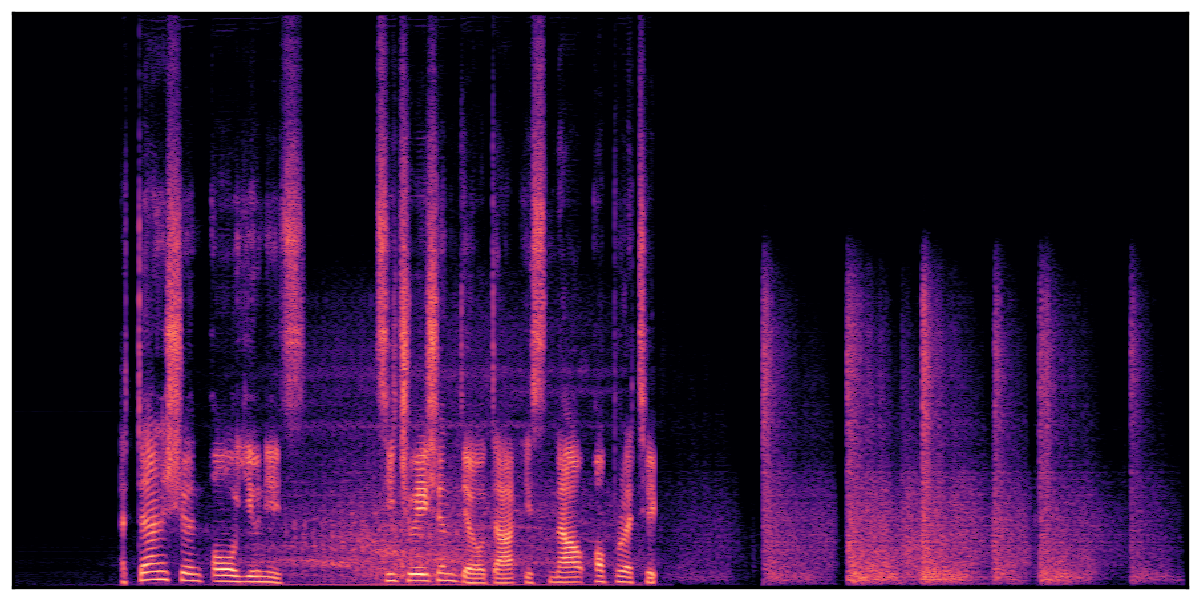
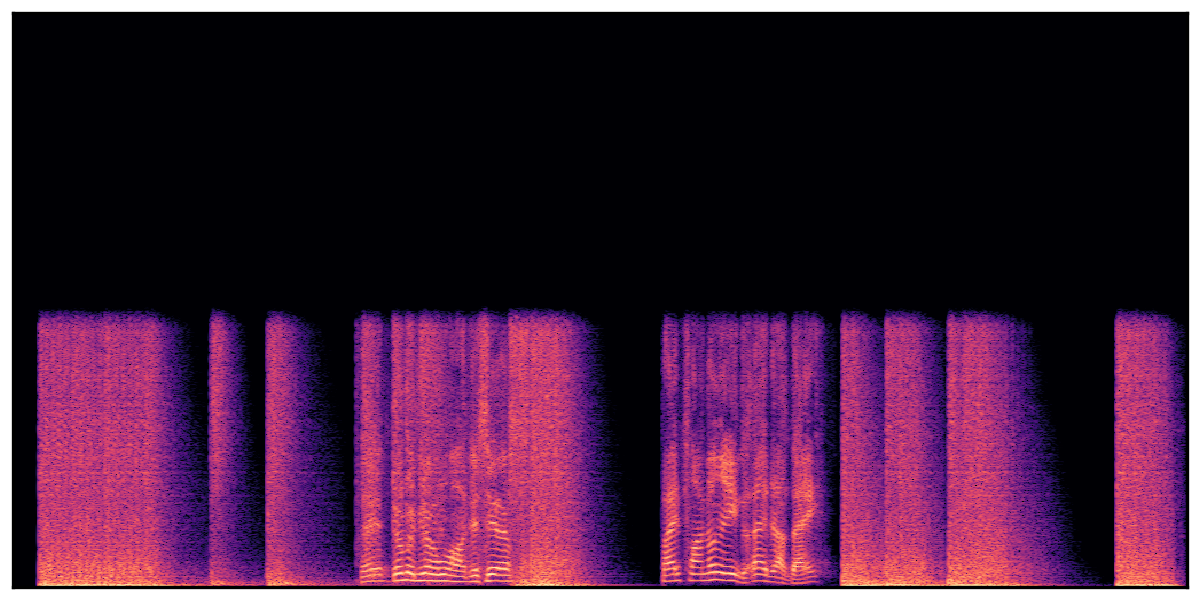
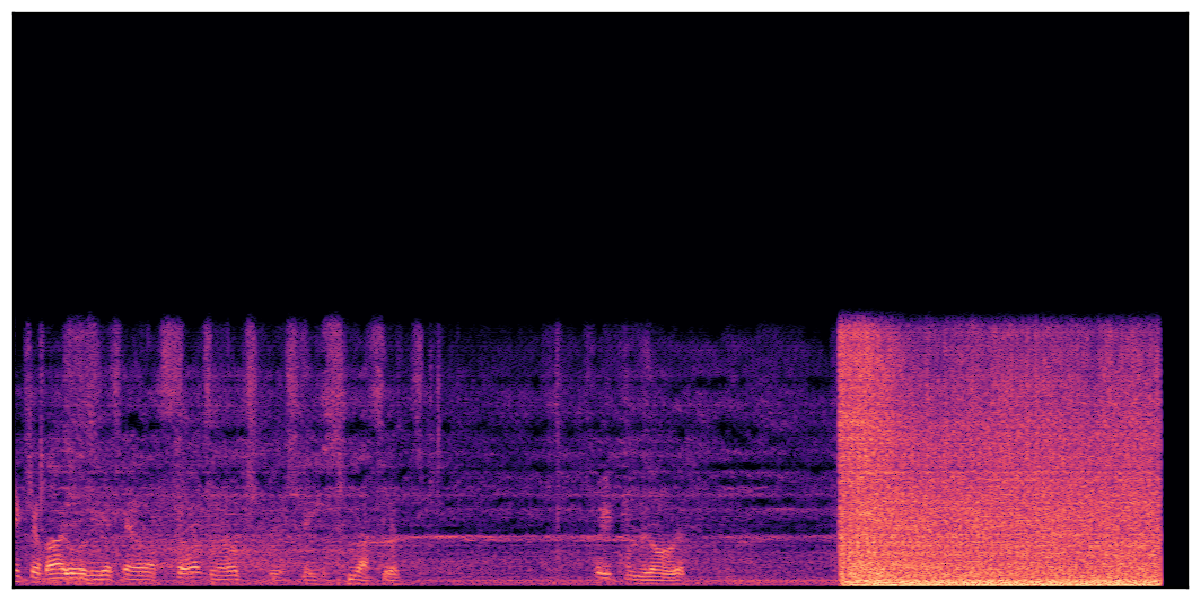
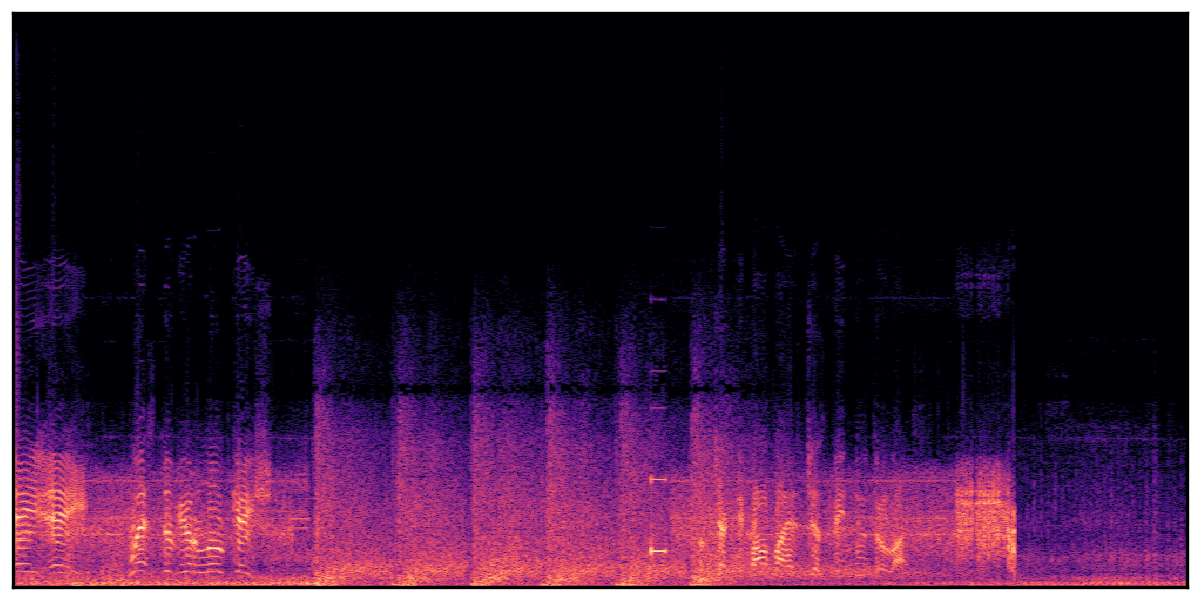
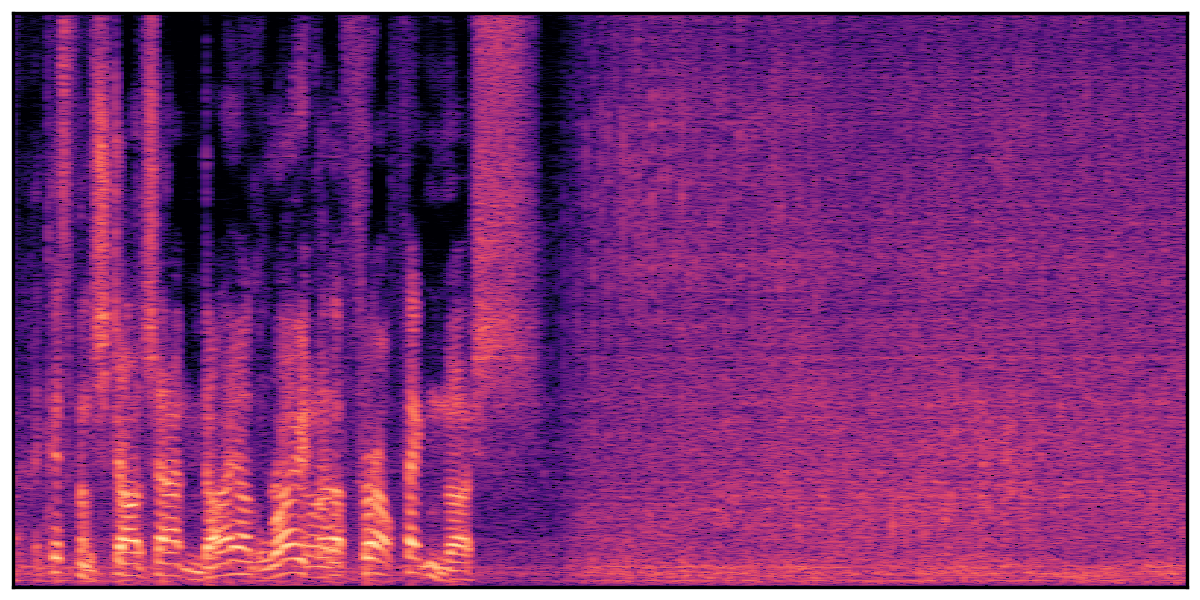
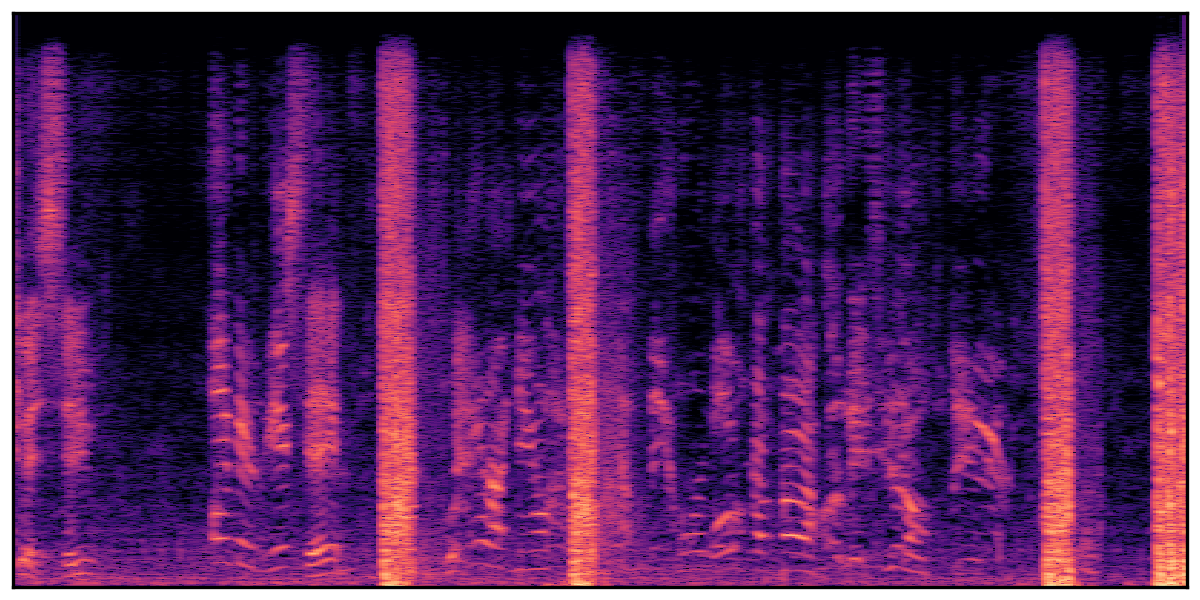
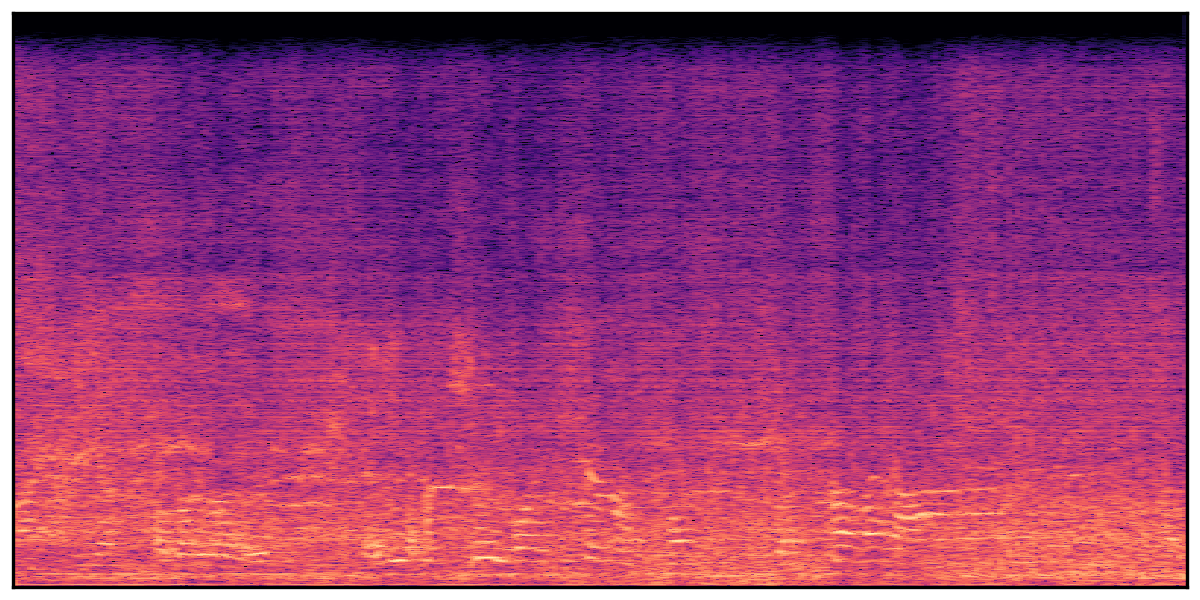
We present audio samples generated by WavJourney in comparison to SOTA text-to-audio generation methods on AudioCaps dataset. WavJourney demonstrates superior performance over SOTA methods, particularly when conditioned on intricate text descriptions. It even stands on par with the ground truth. The compositional design enables WavJourney to model the complex spatio-temporal acoustic relationships among multiple sounds.
There are seven audio clips for each row: (a) Generated audio clips by WavJourney (b) Generated audio clips by AudioLDM. (c) Generated audio clips by Tango. (d) Ground truth audio in AudioCaps dataset. (e) Generated audio clips by AudioLDM2. (f) Generated audio clips by Make an Audio. (g) Generated audio clips by AudioBox. |
||||||||||||||||||||
|
Audio Caption: ''A man talking followed by a goat baaing then a metal gate sliding while ducks quack and wind blows into a microphone '' |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Audio Caption: ''A train running on a railroad track followed by a vehicle door closing and a man talking in the distance while a train horn honks and railroad crossing warning signals ring
'' |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
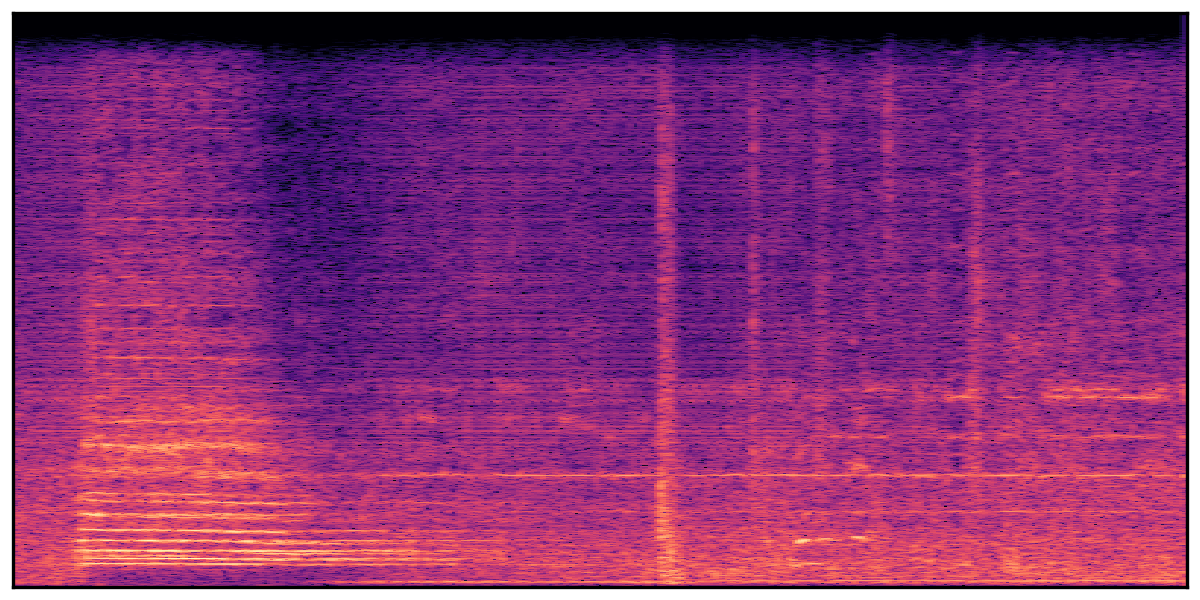
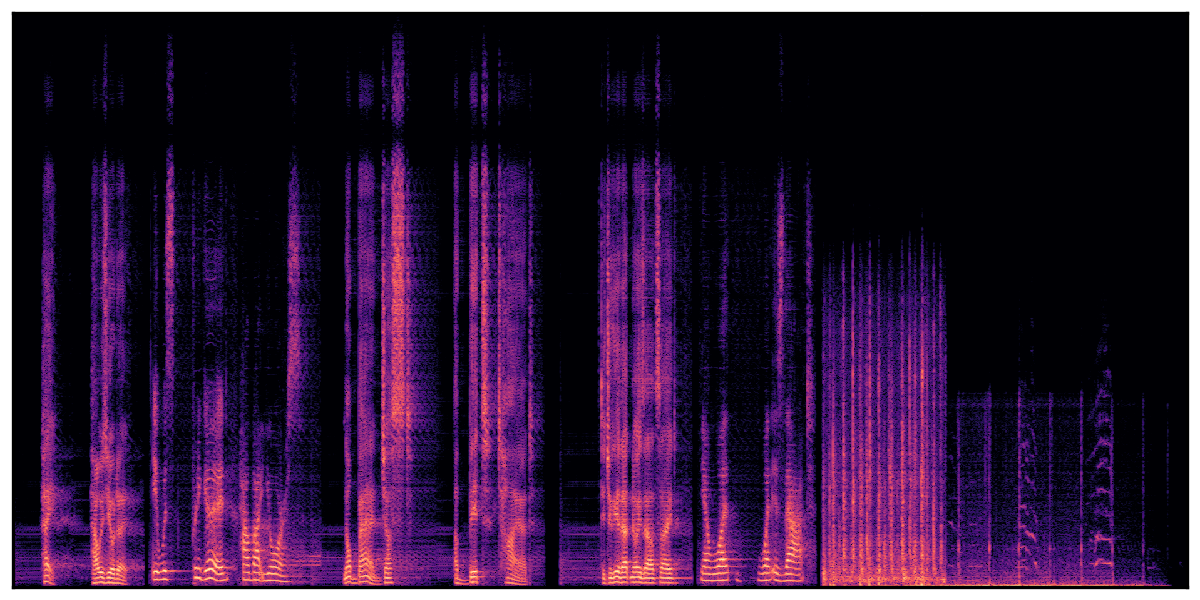
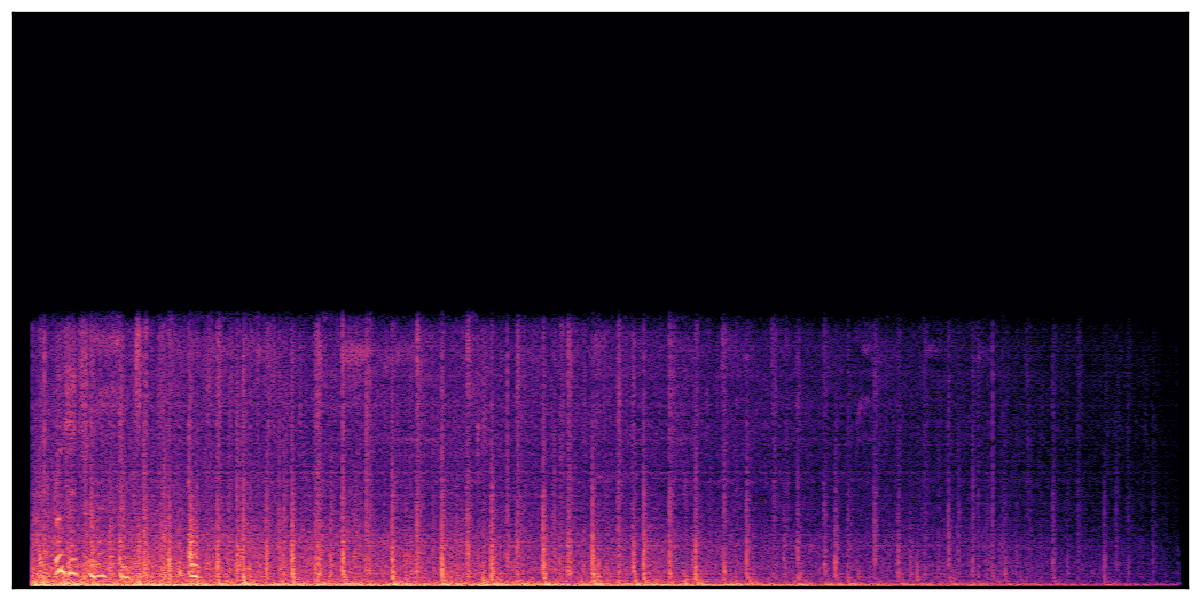
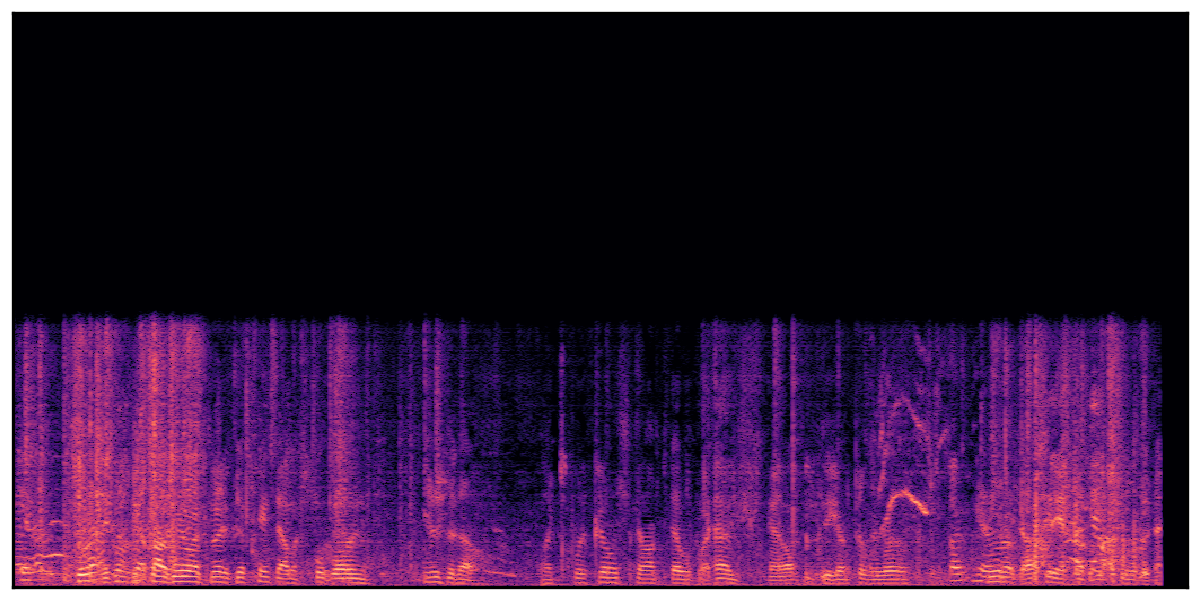
Audio Caption: ''A man speaking followed by a woman talking then plastic clacking as footsteps walk on grass and a rooster crows in the distance '' |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Audio Caption: ''A man speaking over an intercom as a helicopter engine runs followed by several gunshots firing '' |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|